Tuesday, November 1
All about JOINs, my favorite part about SQL. We’ll cover the syntax, I’ll try to show them in real-life exercises. And we’ll have plenty of homework on it for next week.
Agenda
Homicide/Art of Access Readings Part 2 and More
SQL Joins for estimating gender and Hollywood power
Assignments
Homework: SQL Joins, Salaries, and Baby Names
Homework: Why does Ryan Shapiro have so many documents?
All about joins??
I apologize, I spent way too much time gathering datasets for use in join-exercises that I didn't get a chance to revamp how I explained the topic. The past lessons work fine, I just would rather have them be more topical:
- 2015: An introduction to joins and INNER JOINs – on second thought, this one was a bit meta.
- 2014: Basic SQL Inner joins – this one is nice, the main drawback is that it's written in MySQL, though the differences are few.
The homework assignment for today is a long walkthrough with most of the answers done for you. There's also a lesson (that needs editing) on using the babyname data to join gender data to Hollywood Reporter's 100 Most Powerful List, to make it trivial to see the gender imbalance.
Joins as a boring fact of the data world
JOINs, as a way to bring data together, are necessary because real-world systems find it more efficient to separate data into separate systems. We've seen a low-level version of this with the SF restaurant scores database, which separates data for businesses, inspections, and violations into separate tables.
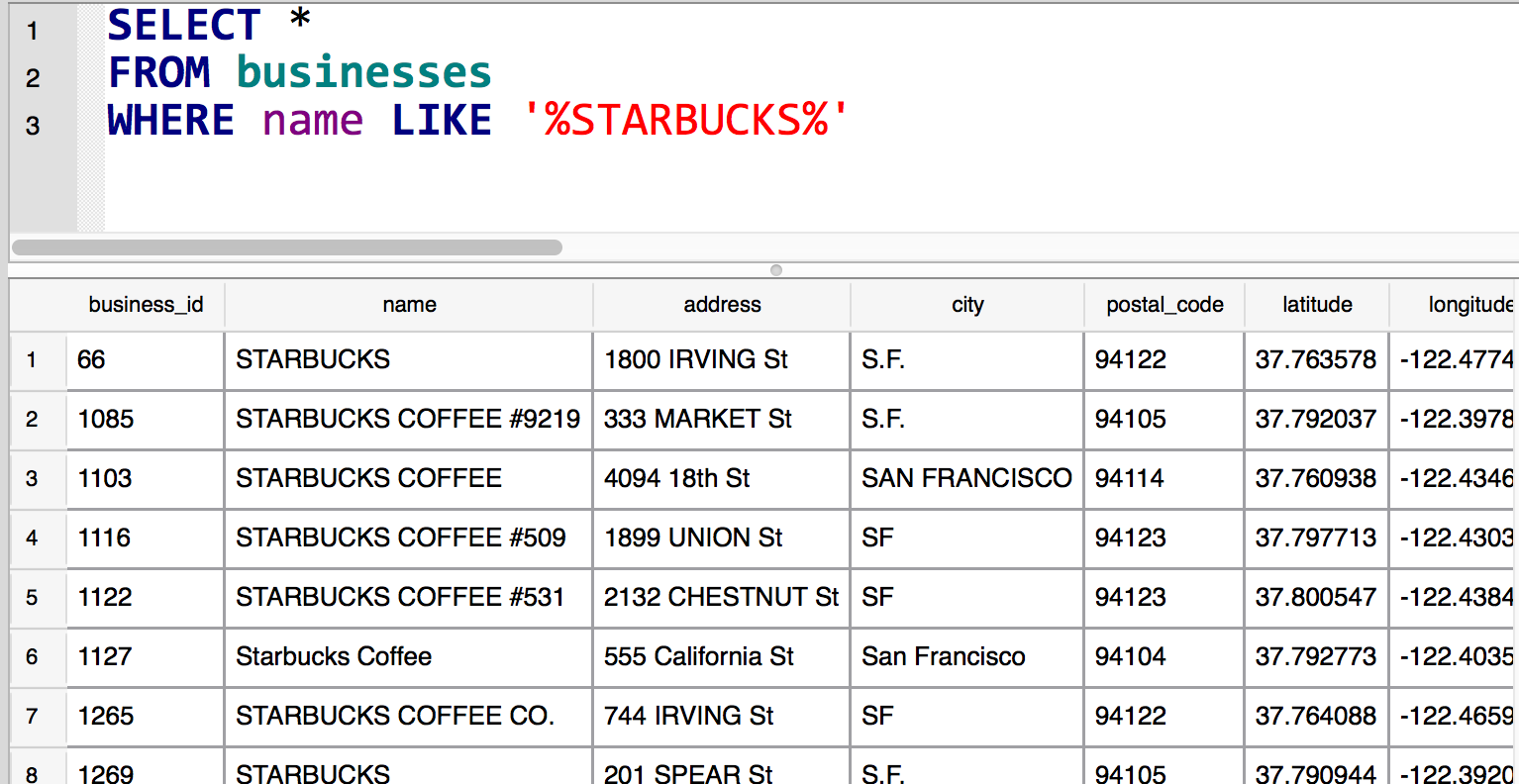
If I have access only to businesses, then I have access only to boilerplate information.
SELECT *
FROM businesses
WHERE name LIKE '%STARBUCKS%';
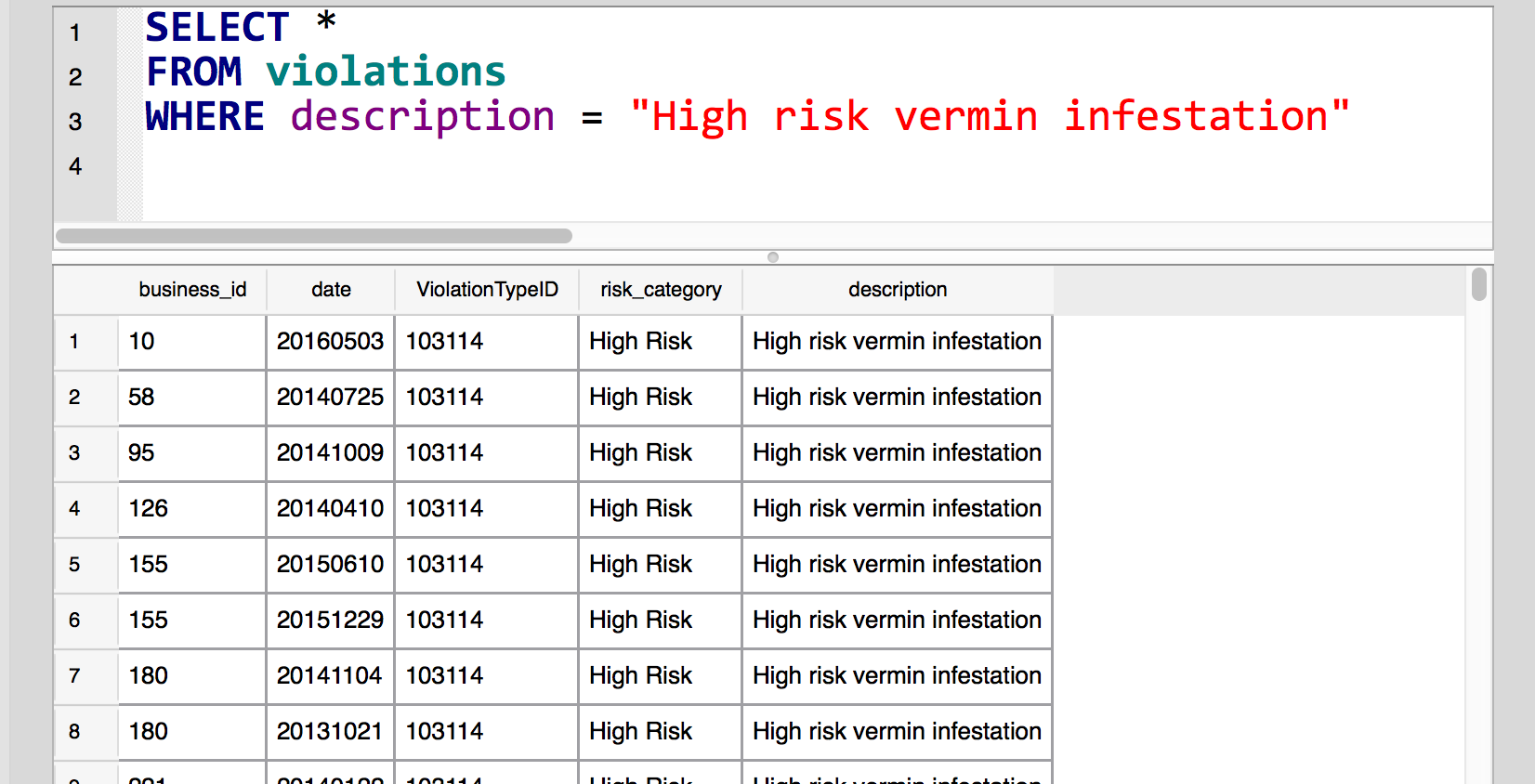
While violations has a lot of the interesting dirt, it has none of the context we need for discerning the safety of businesses. We get only violation descriptions, connected to meaningless numbers:
SELECT *
FROM violations
WHERE description = "High risk vermin infestation";
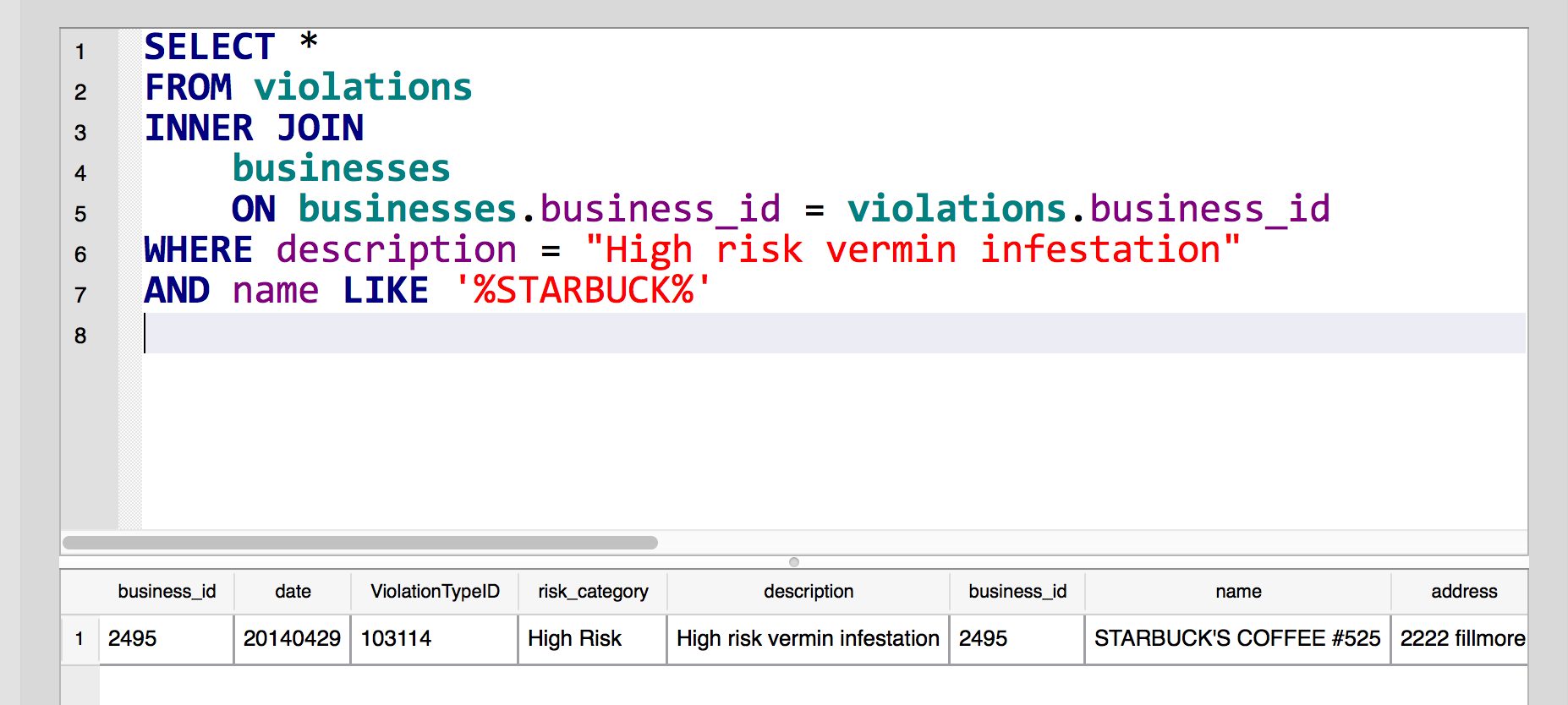
What would make the two nearly-useless tables interesting? If we could put the text of the violation next to the name of the business that failed in food safety. And that's all a JOIN does:
Joins in journalism
That said, the concept of JOINs in a commercial/enterprise system isn't often exciting. In the following SQL query:
SELECT *
FROM violations
INNER JOIN
businesses
ON businesses.business_id = violations.business_id
WHERE description = "High risk vermin infestation"
AND name LIKE '%STARBUCK%'
How did I know to join on business_id? Because that's the way the system was designed. Doesn't take much creativity, and there's not much else choice.
But in journalism, there aren't ready-made systems. Journalists have to think of ways to JOIN different datasets, and the JOIN is not as clean as it is in a tech company's database system.
But the tradeoff is that there are many ways to surprise people who can't think outside of a database. But learning JOINS is very useful, even if most of your work is not in SQL. It's a very concise way to describe how data, events, and facts can be connected.
The syntax isn't the easiest thing, but it more than pays off.