Homework: SQL Joins, Salaries, and Baby Names
This is a walkthrough as exercise, trying out some SQL JOINs, and slight practice on data-wrangling outside of the database.
-
A Google doc named
sql-joins-salarieswith the SQL and results for every query (screenshot if you must) -
Every query gets its own page.
-
On the cover page, list what city/jurisdiction you used.
-
Create a new Google Document (i.e. Word document) and name the file:
sql-joins-salaries -
Choose a California city/jurisdiction and download its 2015 salary data from Transparent California.
-
Clean the payroll data (spreadsheet recommended) so that it has a first_name column
-
Import it into a table in your own SQLite database
-
Answer the queries at the end of the walkthrough, paste the answers (SQL and results table) into the Word doc.
The database of gendered baby names
For this homework, you'll probably want to use this provided database:
You'll need the gendered_babynames table; you can ignore the thr_power_list table.
For context, read the lesson /tutorials/sql-joins-example-thr-power-gender
Remember that you have to produce a Google Doc with all the code/answers to the query at the bottom.
Thinking about salary data
This exercise is meant to acquaint you with the characteristics and quirks of salary data. The queries are meant to be straight forward, but you should be pondering the kinds of things you could analyze if you had more than one year's worth of one city's data to look at…
If you pick a city that has seemingly outrageous overtime or benefits packages, an easy approach is to see how much of an outlier they are among other cities and across years.
Transparent California
While California state publishes payroll data at publicpay.ca.gov, Transparent California pushes the ball by requesting and publishing payroll data with names on it. The difference in structure, and pluses and minuses between the 2 datasets could be its own lecture.
But it's enough to say that having names with the data allows for more worthwhile analysis, even if you don't personally know anyone on payroll.
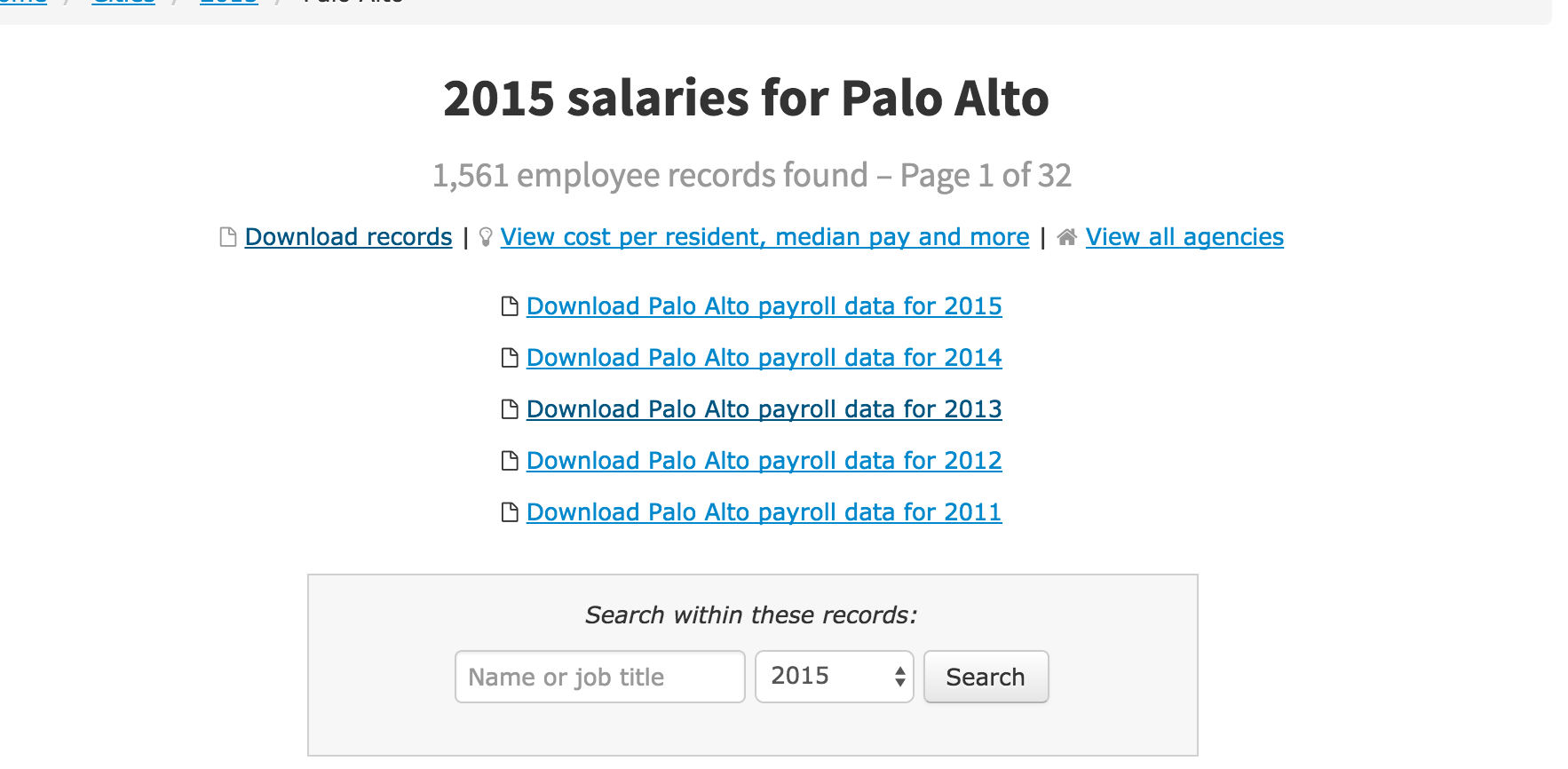
Here's the top-paid Palo Alto city employees from TC's 2015 upload:
Downloading bulk data
TC's website is useful and valuable enough on its own. But they go the extra mile by providing bulk CSV files for download. For any given city or entity, there should be a Download records, which reveals links to each year's CSV for a given city:
For this homework assignment, download the latest dataset from a city, preferably 2015. Unfortunately, the data format changed over the years, and this is to brief an exercise to get into the fun of cleaning/normalizing legacy data.
Breaking names apart
To be sure, names are way more complicated than we've been led to believe. Naming things (and dealing with how others have named things) will likely be the hardest part of your data science/computational journalism life.
That said, one of my biggest pet peeves in day-to-day spreadsheets is when people don't take the time to split out the first and last name (if not the middle). This is what's going on in payroll data hosted by Transparent California:
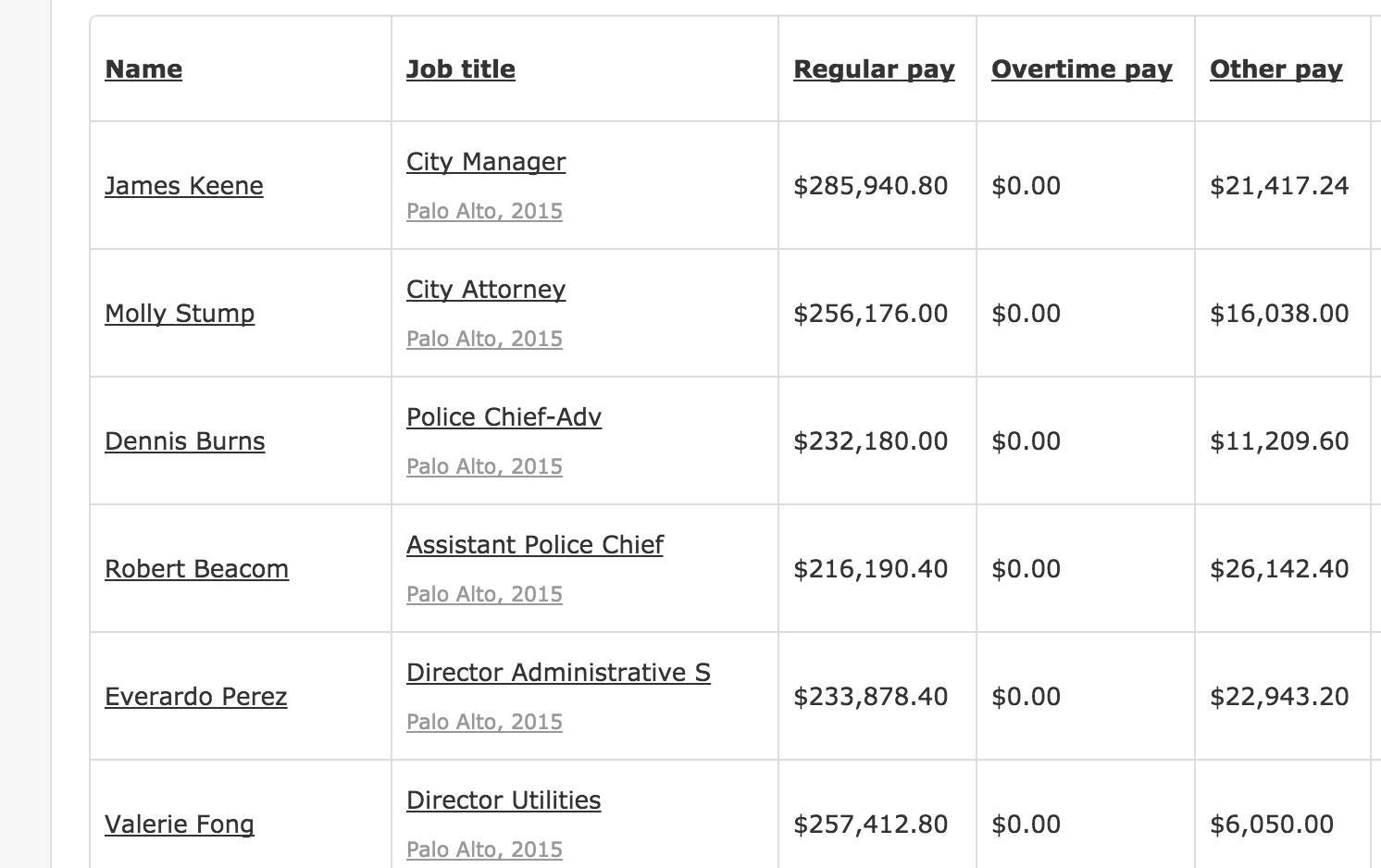
At a glance, it seems we can probably get what we want by assuming that for most rows, the first name and last name are split by a space (though there are obvious exceptions, such as Mary Jo Smith). To get separate first and last name columns we just need to apply a function to that name column.
Unfortunately, we won't be doing it in SQLite.
Wrangling data using a spreadsheet
SQLite is an amazing database (checkout this Changelog podcast with its creator) and will likely outlive all of us. That said, it most definitely is not a tool for the efficient wrangling and cleaning of data.
That it lacks a SPLIT function is reason enough to export data from SQLite into spreadsheet land.
We'll get into SQLite soon, but first, let's do data work with Google Sheets. Up
Splitting and making room
This should feel familiar now (reference for a refresher). Something like:
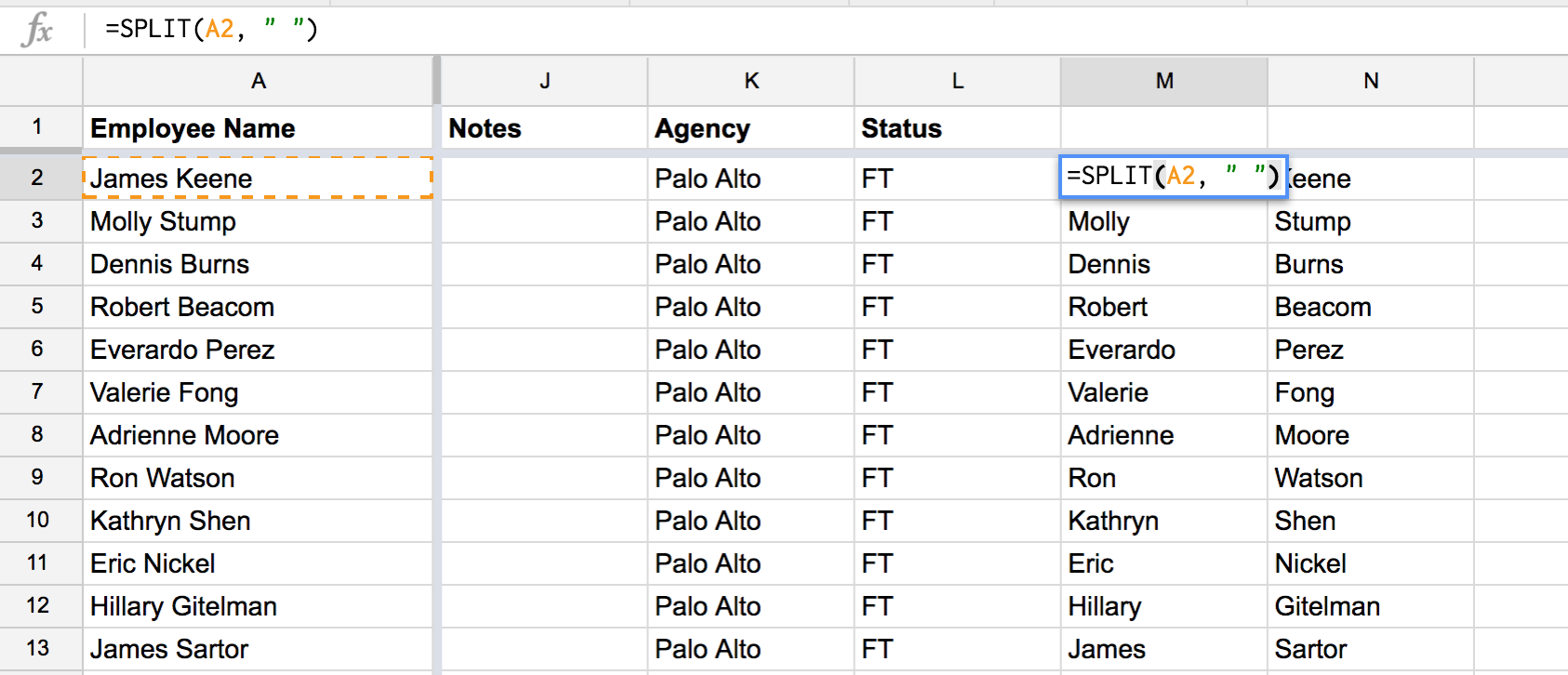
=SPLIT(A2, " ")
However, SPLIT is a little funky in that executing it will spill its results across adjacent cells. If cell A had 8 spaced words, then 8 cells in that row are going to get overwritten.
Since some names may have many spaces, we don't know how many columns to insert. The easiest way to get around this is to do the SPLIT at the other end of the spreadsheet (i.e. not next to the A) column.
Then you have all the room in the world:
Cutting out the dead weight
If you scroll, you'll see that names are indeed more complicated than just first name and last name:
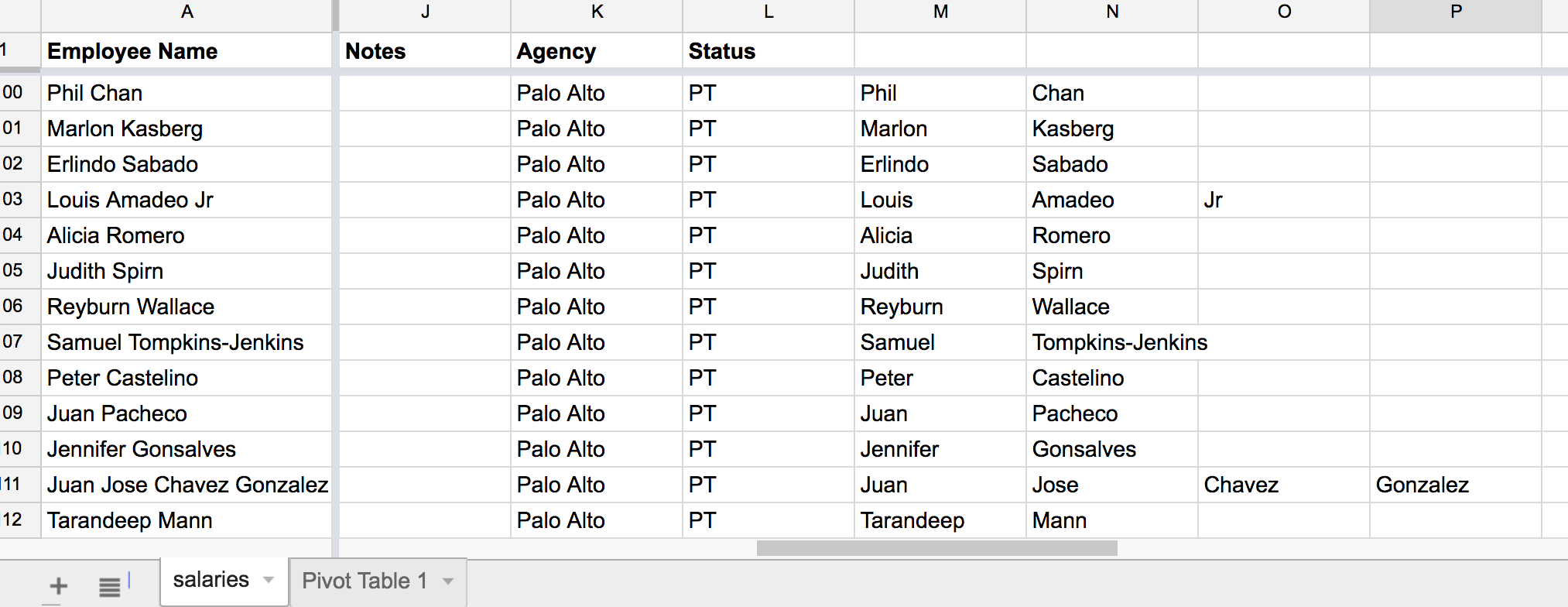
Databases, as we know, aren't know for being flexible. It's going to be a real pain to deal with n-number of partial names.
So let's make it easy. Let's denote the first part of the name to be the first_name column. And then delete everything else. Cleaning up names requires more sophisticated tools (mostly, determination), which is not important to us now.
So let's make the import-to-database as easy as possible.
Make sure all columns to the right of the first_name column are wiped out:
Google Sheets quirk: The undying column
If you're like me, in which the first_name column is column M, and which also holds the SPLIT formula, you'll find that columns N onward will forever regenerate.
That's because column M contains a formula, which is always executing, including filling out columns N and so forth.
The easiest way to fix this (replace the column with literal values):
1. Highlight your first_name column
2. Select Copy and copy the entire column
Leave the column highlighted.
3. Go to the Edit menu, then the Paste Special submenu, then Paste Values
This should overwrite first_name, but with the same values:
If you inspect the first_name cells, you'll see that it contains just literal values – no formulas or other meta-spreadsheet content.
Export to CSV
Finally, export and download your salaries table as CSV.
Importing into SQLite
By this point, you should have downloaded the database with the table of gendered_names: thr-gendered-babynames.sqlite
I recommend using DB Browser as your client. Open up the above-downloaded SQLite database. You should see 2 tables, of which only gendered_names is relevant.
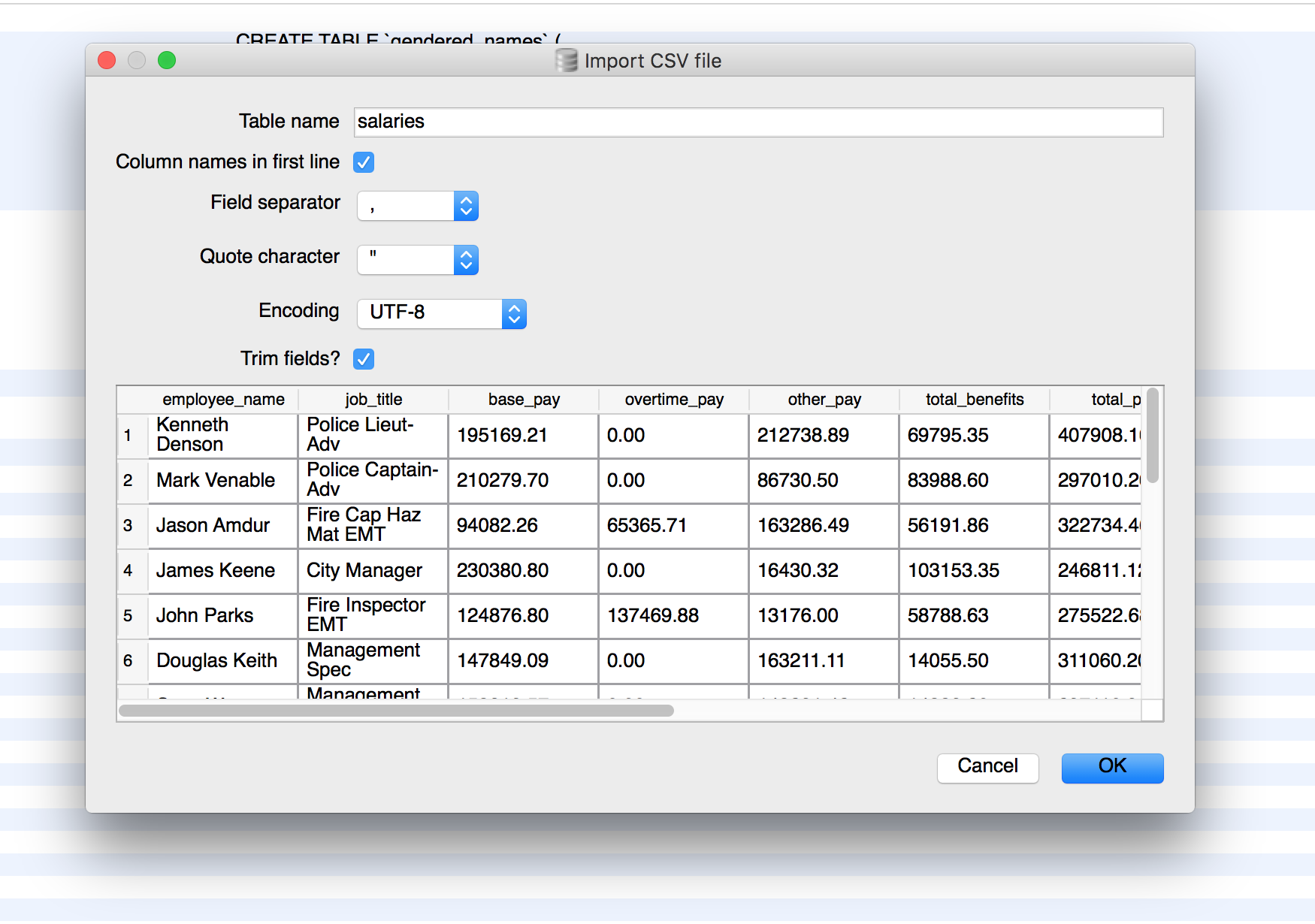
The import popup should be straightforward. I'm assuming you named your table salaries:
SQLite and its painful love of TEXT
OK, this might be the most painful part of the lesson. Depending on what was in your spreadsheet, and how it was imported/exported, DB Browser's import process may be inclined to every column as TEXT, even the ones dealing with salary.
What does this have to do with you? Try doing a sort by money, such as total_pay_benefits
(note that I alias the cumbersome column name to total_pay_benefits because who knows how SQL will interpret the ampersand)
SELECT EmployeeName, JobTitle,
"TotalPay&Benefits" AS total_pay_benefits
FROM salaries
ORDER BY total_pay_benefits DESC
LIMIT 10;
When numbers are treated as text, they are sorted alphabetically:
| employee_name | job_title | total_pay_benefits |
|---|---|---|
| Mary Sekator | Administrative Associate | 99914.43 |
| Thanh-Tran Nguyen | Payroll Analyst | 99778.22 |
| Richard Hirano | Desktop Technician | 99720.17 |
| Vincent Vasquez | Gas System Tech | 99699.05 |
| Julie Weiss | Environmental Spec | 99695.69 |
| Gregory Smith | WQC Plt Oper II | 99659.76 |
| Jason Griffin | Recreation Leader II | 9948.74 |
| Joe Berkey | Meter Reader | 99479.61 |
| Ariel Berson | Prod Arts/Sci Prog | 99405.11 |
| Mary Grace Castor | Human Rsrce Asst Cnf | 99340.08 |
Note that a non-Bay-Area resident might look at this dataset and think it was working — 999915 could buy a lot in other parts of the country. But those of you who live here, you know that 99914 is not a high wage for Palo Alto. Or that among Palo Alto's highest paid employees would be a meter reader.
Consider CAST and being explicit
The proper SQLite way to handle this would be to wrap all your number fields in a CAST function, in which you tell SQLite, Hey, this is a number!. Learning CAST is actually nice because it further acquaints you with how things work in computer-land, while giving you more practice with being explicit with how you code.
Here's the SQLite documentation on CAST.
Here it is in action:
SELECT EmployeeName, JobTitle,
CAST("TotalPay&Benefits" AS NUMERIC) AS total_pay_benefits
FROM salaries
ORDER BY total_pay_benefits DESC
LIMIT 10;
And there's the big salaries:
| EmployeeName | JobTitle | total_pay_benefits |
|---|---|---|
| Kenneth Denson | Police Lieut-Adv | 477703.45 |
| Mark Venable | Police Captain-Adv | 380998.8 |
| Jason Amdur | Fire Cap Haz Mat EMT | 378926.32 |
| James Keene | City Manager | 349964.47 |
| John Parks | Fire Inspector EMT | 334311.31 |
| Douglas Keith | Management Spec | 325115.7 |
| Scott Wong | Management Spec | 311450.19 |
| Dennis Burns | Police Chief-Adv | 309138.22 |
| Michael Verga | Fire Cap Haz Mat EMT | 294068.42 |
| Thomas Newland | Fire Inspector EMT | 289664.24 |
Learning CAST and using it regularly will help you in the long run, so don't shun it because of the extra typing…
DBrowser table alteration
That said, people don't really like writing extra function calls if they can help it.
One of the conveniences that DB Browser has, but that SQLite in general does not – is the ability to point-and-click and change a table's structure. This is nice when you've created a table and screwed a small thing up.
It's helpful in our situation because we can alter our salaries table to have proper numeric columns, which is something you can't really do in base SQLite without wiping out the table and re-importing.
That said, it's highly dependent on DB Browser, the fancy client, i.e. it's not a core SQLite skill. Today it works, maybe it won't later on.
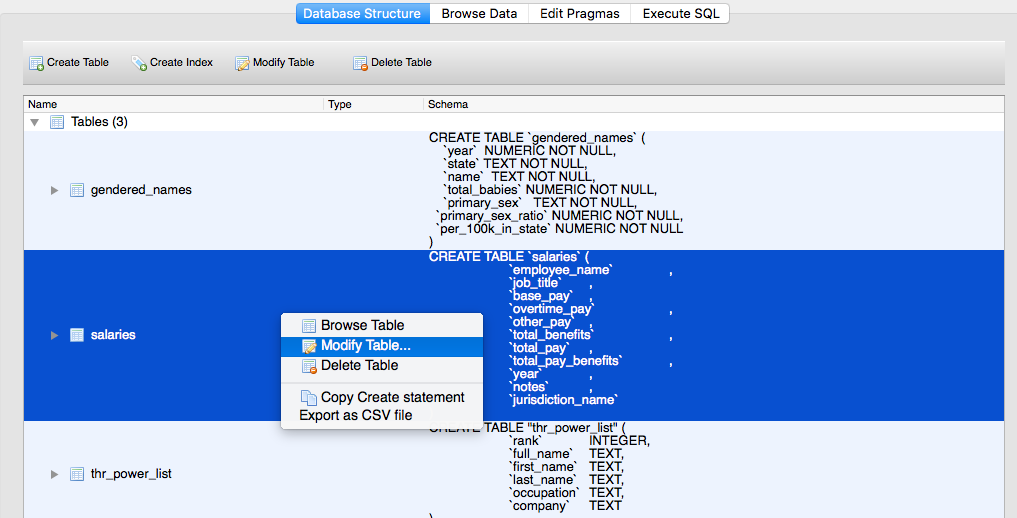
You can get started by going to the Database Structure panel and right-clicking the salaries entry:
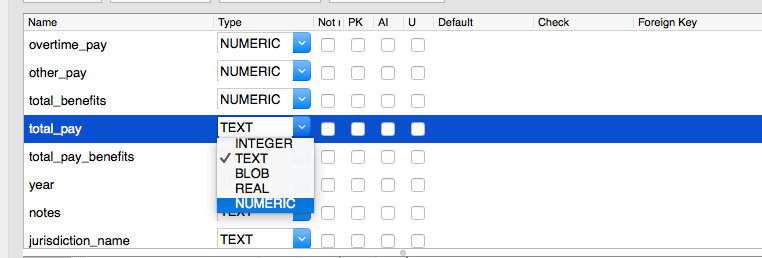
Then, for each field you want to be a number, change the dropbox from TEXT to NUMERIC:
Hit OK
Remember to save in DB Browser
(just another quirk, don't get bogged down in this detail)
Another piece of trivia for DB Browser that doesn't exist in other SQLite implementations, for better or worse. Anytime you change up a database or table, such as add a table, import data, delete data, etc, be sure to save your work (like a Word document) with Command-S. DB Browser has this feature in which it doesn't write things immediately. For people who are prone to making mistakes, this is great. For longtime SQL users who are used to the database getting things done on command, it can be quite confusing. It shouldn't impact you hugely as you're learning SQL.
Query the payroll
By now, you should have a database file with:
- A
salariestable, which includes 1 year of data and afirst_namecolumn - The
gendered_namestable.
Here are some casual queries to explore the data.
(These queries assume your salaries data table has proper NUMERIC columns, or if not, I assume you know how to use the CAST function
Instructions
For all of these queries, I want you to type out the queries, get a result. And then, in the Google doc that you turn in, I want to see the data. For most of you, the easiest way to do this is to screenshot the results and paste it into the Word doc.
Some of the queries are already written – that's OK, type them out on your own. Other queries need to be completed.
Number of full time employees
SELECT COUNT(*)
FROM salaries
WHERE Status = 'FT';
Show the number of Full-Time vs Part-Time employees
Same as above, but WHERE is unnecessary. And, we need a GROUP BY. Here's a start:
SELECT COUNT(*)
FROM salaries
...
The 5 employees who make the most Total Pay compared to their base pay
- Include a column that shows how high that ratio is
- We'll have to filter out part-time employees for this
SELECT EmployeeName, JobTitle,
BasePay, TotalPay,
(TotalPay / BasePay) AS overbase_ratio
FROM salaries
ORDER BY overbase_ratio DESC
WHERE STATUS = 'FT'
LIMIT 5;
How many full-time employees have a (TotalPay/BasePay) ratio over 1.5?
Similar to the above query, except you just need 1 column:
SELECT COUNT(*)
FROM salaries
...
What are the 5 most common job titles
Just do a GROUP BY on job title:
SELECT GROUP BY(JobTitle), COUNT(*) as jcount
FROM salaries
ORDER BY jcount DESC
LIMIT 5;
Of the employees with 'Police' in the title, what is their average salary, overtime, etc?
Here's a start:
SELECT AVG(OverTimePay), AVG(OtherPay), AVG(Benefits), AVG(BasePay)
FROM salaries
...
The result shouldn't be more than one row.
How many employees are management level
There's no right or wrong answer to this. Look at the various job titles (I'd start with the highest paid people) and see what terms are used, e.g. Chief, City Manager, Director, and so forth.
Your query will probably have a lot of LIKE clauses and OR keywords.
What is the percentage of full-time employees who make over $150,000 in total pay?
This is a nice example of how to use a subquery to store a scalar value (typically, a single number).
The scalar in this case is the total number of FT employees:
SELECT COUNT(*) FROM salaries WHERE Status = 'FT';
In fact, the number of $150K FT employees is a scalar, i.e. just a count:
SELECT COUNT(*) FROM salaries
WHERE Status = 'FT' AND TotalPay > 150000;
You can plug that query right into the main query that counts the $150K-making employees. But yeah, that's not too pretty:
SELECT 100.0 * COUNT(*) /
(SELECT COUNT(*) FROM salaries WHERE Status = 'FT') as ratio
FROM salaries
WHERE Status = 'FT'
AND TotalPay > 150000;
Query and join the payroll
Assuming you're relatively new to JOINS, this section will take it easy. Make sure you do the queries. And pay attention to the details.
List the name, the probable sex, and the total salary + benefits of 5 highest paid employees
SELECT EmployeeName, primary_sex,
"TotalPay&Benefits" AS tbpay
FROM
salaries
INNER JOIN
gendered_names
ON gendered_names.name = salaries.first_name
ORDER BY
tbpay DESC
LIMIT 5;
Quick tip about specifying tables
Note that it's possible to write the above query more vaguely, i.e. removing the table-prefix for gendered_names.name and salaries.first_name:
SELECT EmployeeName, primary_sex,
"TotalPay&Benefits" AS tbpay
FROM
salaries
INNER JOIN
gendered_names
ON name = first_name
ORDER BY
tbpay DESC
LIMIT 5;
Why does that work? Because name is only used in gendered_names, likewise, with first_name and salaries. It's generally a good habit to include table names, but there's a definite balance between being explicit and adding a ton of unneeded clutter:
SELECT salaries.EmployeeName,
gendered_names.primary_sex,
salaries."TotalPay&Benefits" AS tbpay
FROM
salaries
INNER JOIN
gendered_names
ON gendered_names.name = salaries.first_name
ORDER BY
tbpay DESC
LIMIT 5;
List the gender breakdown for employees paid over $150K
Same query as a previous query, except we use a GROUP BY, and we're getting an aggregate count (no need to get the names or salary):
SELECT primary_sex,
COUNT(*) AS pcount
FROM
salaries
INNER JOIN
gendered_names
ON gendered_names.name = salaries.first_name
WHERE TotalPay > 150000;
The only thing that's missing is the GROUP BY, which always comes after the WHERE, which means it also always comes after any JOINs:
SELECT primary_sex,
COUNT(*) AS pcount
FROM
salaries
INNER JOIN
gendered_names
ON gendered_names.name = salaries.first_name
WHERE TotalPay > 150000
GROUP BY primary_sex;
Count of FT employees by gender, and other salary metrics
Just the same kind of JOIN and GROUP BY as before, but with more metrics:
SELECT primary_sex,
COUNT(*) AS pcount,
AVG(TotalPay) AS avg_total_pay,
MIN(TotalPay) AS min_total_pay,
MAX(TotalPay) AS max_total_pay
FROM
salaries
INNER JOIN
gendered_names
ON gendered_names.name = salaries.first_name
WHERE Status = 'FT'
GROUP BY primary_sex;
Average over-base-pay by gender
Let's close up with a fairly easy and derivative query: get an average of TotalPay/BasePay by gender for full-time employees. See if you can work this out on your own.
It may even help starting out a basic SELECT and starting with the gendered_names table instead of salaries:
SELECT primary_sex
FROM gendered_names;
Add the GROUP BY, though there's nothing to agg:
SELECT primary_sex
FROM gendered_names
GROUP BY primary_sex;
Let's add the JOIN:
SELECT primary_sex
FROM gendered_names
JOIN salaries
ON salaries.first_name = gendered_names.name
GROUP BY primary_sex;
Now we have money-fields to AVG…and we're done:
SELECT primary_sex,
AVG(TotalPay/BasePay)
FROM gendered_names
JOIN salaries
ON salaries.first_name = gendered_names.name
GROUP BY primary_sex;