Reading Your Browser's History with SQLite
How the SQLite database is used in billions of real-world applications today is of little relevance to us in this class. But the web browser is a easy-to-understand scenario of how a database gets created and filled.
Know a database, know thyself
Whoever first thought "If you didn't do anything wrong, what do you have to hide?" obviously didn't know SQL.

We study public data because its free, its creation is a result of our tax dollars, and its contents and insights influence our laws and policies.
That said, it's not easy to learn SQL with public data. Before the data is made publicly available, agencies can be overzealous in scrubbing it of the details that are not only interesting, but provide vital context needed to accurately analyze the data. While Menlo Park publishes police stop data, it's almost entirely lacking information about who was stopped – e.g. the age, race, and gender of the subject, while being vague about the reason for the stop and what happened during the stop:
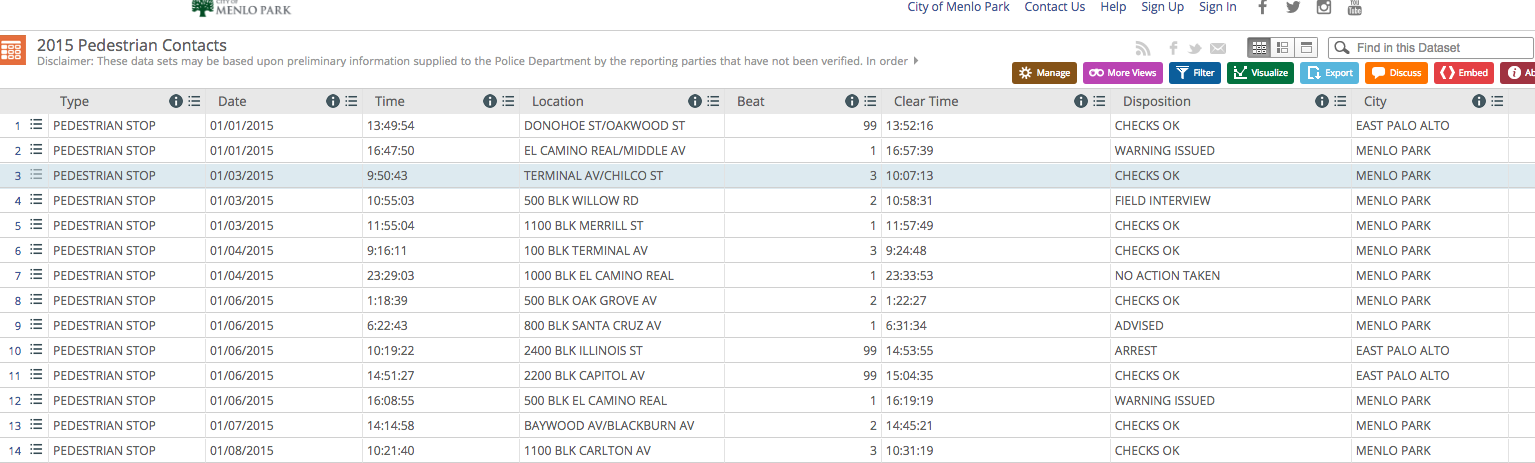
In contrast, every law agency in Connecticut publishes detailed data about every traffic stop, including the age, gender, race, and ethnicity of the driver, the reason the stop was initiated, whether the vehicle was searched, and what, if anything, was found. But this depth of data required the state legislature to care about the problem of racial profiling, and then to pass a law and allocate resources to properly collect the data.
So how do journalists extract insights and powerful stories from even the most benign datasets. The ones who do it well are intimately knowledgeable about what's in the data, what's missing, and everything in the world that that data touches. They already know what they'll find in the data before writing an actual query.
If you're new to journalism, you don't have this advantage. You haven't had the time to build a beat, and then to get the tips and scoops from the officials and folks who know where the stories are. SQL expertise can only do so much.
Data analysis and SQL should feel difficult and foreign when you are working with difficult and foreign data. Luckily for us, knowing SQL opens a vast array of opportunities for practicing analysis on interesting datasets.
For example, if you even occasionally browse the web on your personal computer, then you are in complete ownership of a unique and very personal dataset, the records of which are entirely of your own making: the history of websites you've visited, which conveniently for us, every major browser today stores in an easy to access SQLite database.
Questions to ask
Depending on what browser you use, you'll find out that your browser has recorded a lot more information about you than what websites you've visited. But even if you limit ourselves to collating and counting the URLs that you've visited, what you visit on the web reflects in part your interests, your fears, and even your sleeping habits.
Whether data is personal or public, the basic questions and queries are largely the same.
Start off with questions that get the general outline of the data:
- How many webpage visits total does the History database contain?
- How far back does the database go?
- How many unique URLs did I visit?
- How many unique domains (e.g. www.nytimes.com) did I visit?
- What's the average number of sites visited per day?
- What is the peak hour for my web visiting activity?
Then, use those general numbers to guide more specific and interesting queries:
- What are the domain/website, e.g.
www.nytimes.com, that I've visited most? - How much do I browse on the weekends versus weekdays? Late night versus day time?
- For the web browsing I do late at night, what was the most frequent domain/website?
- What are the sites that I consistently visit after wake up in the morning?
- Where there any days in which I didn't visit a single website? Were there days in which I was browsing the web nearly every single hour?
And finally, ask questions informed from the expert domain knowledge you have about yourself:
- Which weeks were outliers in terms of web browsing? What was going on in my life when I wasn't checking out the web. Or, for weeks in which I seemed glued to my browser, what was I looking at?
- Which sites did I regularly visit in the first month of the dataset that I never visit anymore?
- How did my new job/relationship/computer change my habits?
Data is easy when it is familiar, and being the creator of the data is about as familiar as you can get. But when you know (or think you know) everything about the data, you'll find that you'll have to think more creatively, because it's a waste of time to ask the obvious questions.
For example, if I gave you my database of browser history, you would probably run this as your first query, which is about as specific as it gets:
SELECT *
FROM history_items
WHERE url LIKE '%ashleymadison%';
/* or whatever term corresponds to blackmail material*/
But you probably wouldn't run that query on your own dataset. What's the point? Don't you already know which sites you spend money on, and/or on which you're having lots of fun? money on and having lots of fun. You don't need to write SQL queries to discover what you already.
The fun is in how effortless it is to pose hypotheses, and then to test your assumptions: e.g. "I never visit ESPN.com during the work day.", "I'm very disciplined in cutting of my Internet browsing before bed.", "As an intellectual and deep human, I read many more New Yorker articles than I do Buzzfeed listicles"
Overview of Safari and History.db technical notes
I'll elaborate on some of these steps further in the tutorial. But here's a quick reference for the technical details.
Steps to open Safari's browser history database
- If the Safari browser is open, you might be blocked from opening any of its databases. So start off by completely quitting out of Safari (Keyboard: Command-Q).
- Now we need to get into the folder that contains the SQLite database of browser history. To activate Finder's Go to Folder command, use the keyboard shortcut of:
Command-Shift-G. This also works within the Open Database dialog in DB Browser. - Type in
~/Library/Safarito get to the enclosing directory of the history database. - Inside the
~/Library/Safaridirectory, look for the file namedHistory.db - Open it with your SQLite client.
What does Safari's History.db contain?
There are 6 tables, but for analyzing web browsing activity, there are 2 tables we care about:
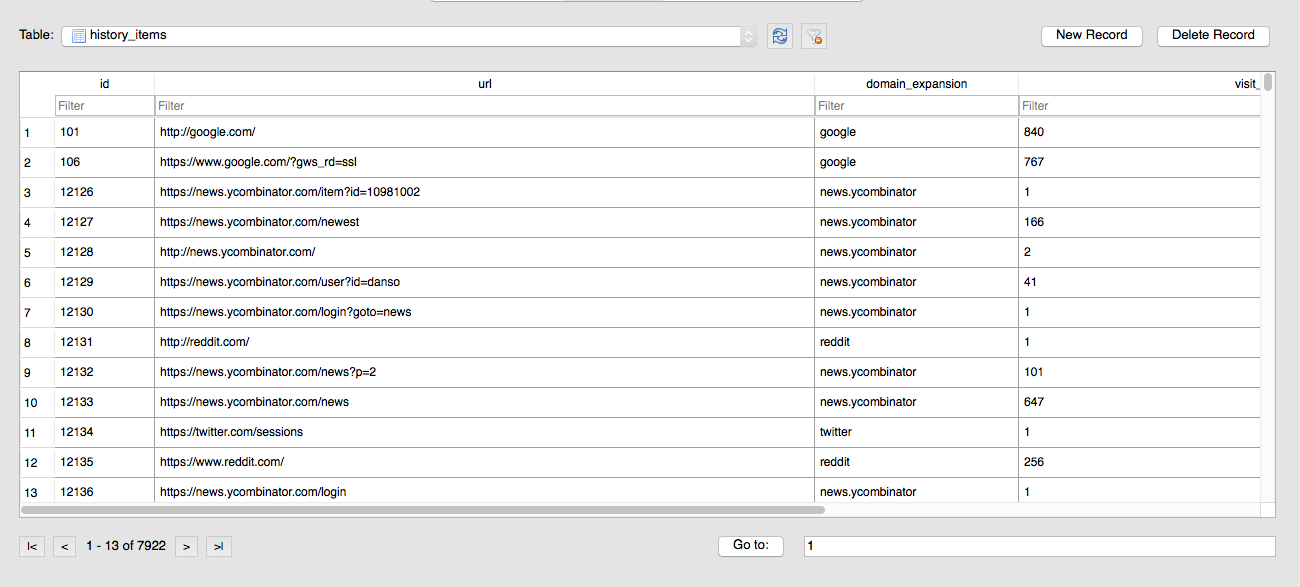
history_items: this table contains a row for every unique URL visited, including an aggregate count of total number of visits. The SQLite client lists the number of rows as 7,922:
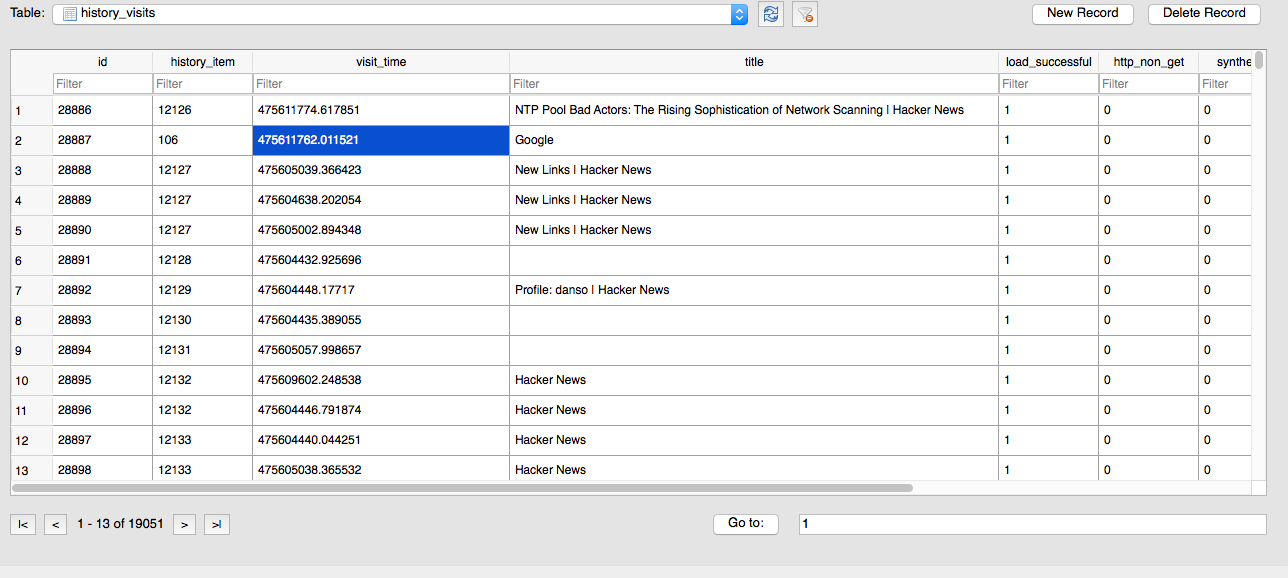
history_visits: this table contains information about each visit, specifically the visit_time and the title of the page, but not the URL itself (a webpage at a given URL can change its title).
Note in the screenshot below that this table contains 19,051 results. Doing some heavily rounded math in my head, on average, I visited each URL a little more than twice:
Joining history_items and history_visits
Rather than repeat the URL information for every separate visit, Safari has URLs in one table, and individual visit records in another. This is good data normalization practice. But it means we have to write extra SQL in order to associate the visit_time field (in the history_visits) table with the actual URLs in history_items.
Here's the general query; don't worry if you don't understand JOIN yet as we haven't covered it:
SELECT
visit_time, title, url
FROM
history_visits
INNER JOIN
history_items ON
history_items.id = history_visits.history_item;
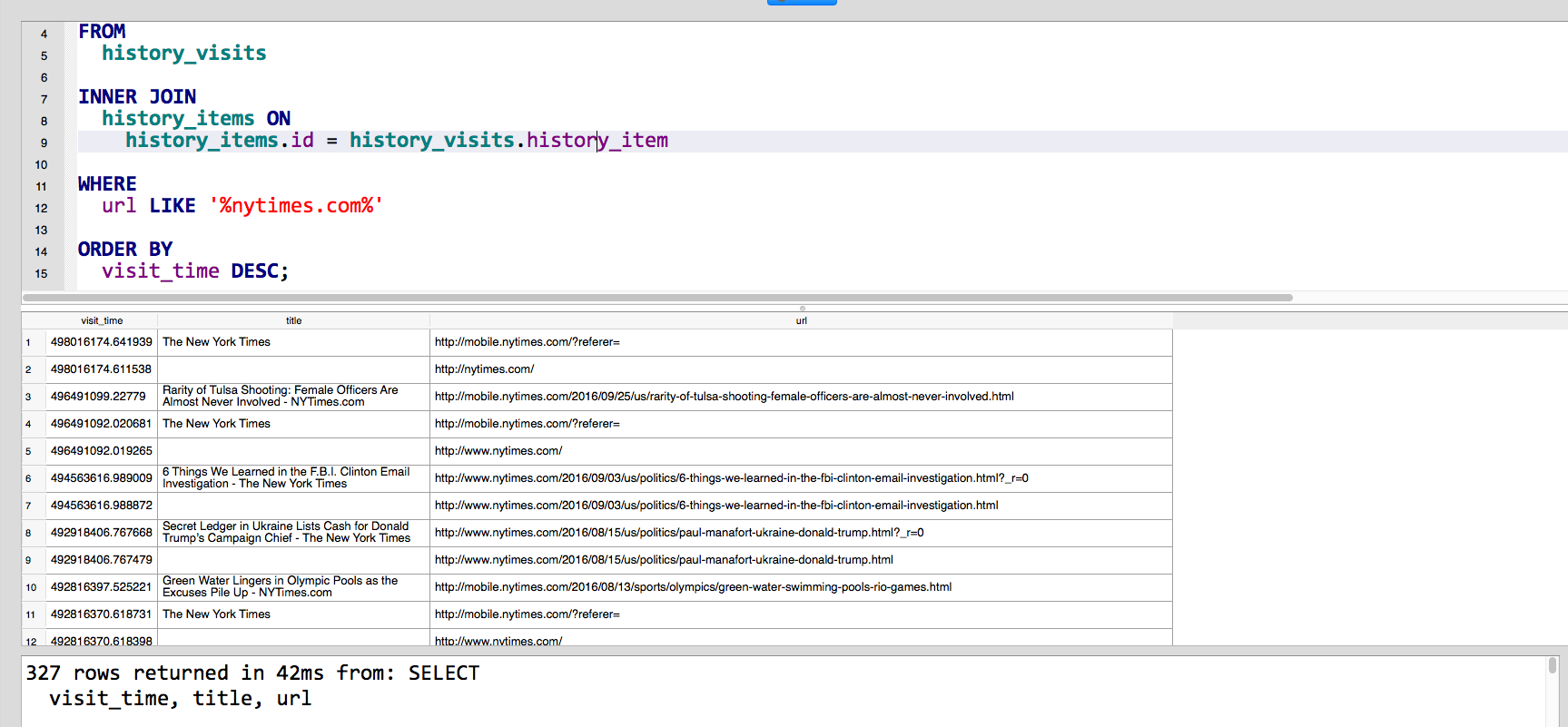
To find every visit I've made to URLs that contain nytimes.com, sorted in order of most recently visited, we add a WHERE clause:
SELECT
visit_time, title, url
FROM
history_visits
INNER JOIN
history_items ON
history_items.id = history_visits.history_item
WHERE
url LIKE '%nytimes.com%'
ORDER BY
visit_time DESC;
Here's what the results look like:
What's with the visit_time?
The visit_time column is supposed to mark the time when a a visit to a website recorded.
The time value is stored as a decimal number: 498016174.641939
To make meaning out of that number, we need to know:
- That the decimal number stored in
visit_timerepresents the number of seconds since the beginning of time. - What exactly is the "beginning of time", according to Safari's database
- how to use SQLite's
datetimefunction to convert time-in-seconds to human-readable time
Credit to this StackOverflow user for having the concise answer:
The function call to datetime to convert Safari's massive decimal numbers into something more relatable is:
datetime(somenumber + 978307200, 'unixepoch', 'localtime')
Here we call the function on its own to translate a single, arbitrary number:
SELECT datetime(498016174.641939 + 978307200, 'unixepoch', 'localtime');
The resulting row is: 2016-10-12 18:49:34
Throwing in a comically large number to convert:
SELECT datetime(19999999999 + 978307200, 'unixepoch', 'localtime');
Result is: 2634-10-11 03:33:19
Back to the actual database, to get a 2-column list of results: the original visit_time, and its human-readable equivalent:
SELECT
visit_time,
datetime(visit_time + 978307200, 'unixepoch', 'localtime')
AS human_readable_time
FROM
history_visits
LIMIT 5;
| visit_time | human_readable_time |
|---|---|
| 498634566.959907 | 2016-10-19 22:36:06 |
| 497304526.620537 | 2016-10-04 13:08:46 |
| 497304503.057944 | 2016-10-04 13:08:23 |
| 497304477.877726 | 2016-10-04 13:07:57 |
| 497304243.063638 | 2016-10-04 13:04:03 |
There's a Spaceballs video and more exposition about time and computers further on down…
Pardon the construction
Note and apologies: I had material that covered the steps for the Chrome and Firefox browsers, too, as well as analysis of social media data. Like Safari, they also use SQLite to store user data and browser history. However, there's enough technical and structural differences between the browsers that I found myself doing way too much research into how the browsers worked, when this is just a lesson about SQL.
Since most students are on Macbooks anyway, and our computer lab is stocked with OS X and Safari, this guide will just contain instructions for OS X 10.6 and Safari. Even if Safari isn't your main browser, you can still experiment with seeing how it stores webpage visits in its History database as I finish updating the specific steps for Chrome and Firefox.
Besides the SQL practice, which should be inherently more interesting than public data that has less personal relevance, there's the big picture concept: even when you are the sole source of data in a dataset, you can still be surprised with how much you've forgotten about yourself.
What is your browser history?
By default, a modern web browser will track every URL you visit. No matter the name of site, the content of the page, how long you lingered to read the page, each page visit is logged by your browser and saved to your computer's file system as a SQLite database.
The History panel
This History data to used to add convenience to your browsing experience. These features of convenience are usually so seamlessly integrated that you may not have even used the browser's dedicated History functionality, and may be unaware that your activity is tracked at all.
But for browser developers, the History feature is apparently important enough to get top-level placement on the browser's menu bar. Here's what Safari's History panel looks like
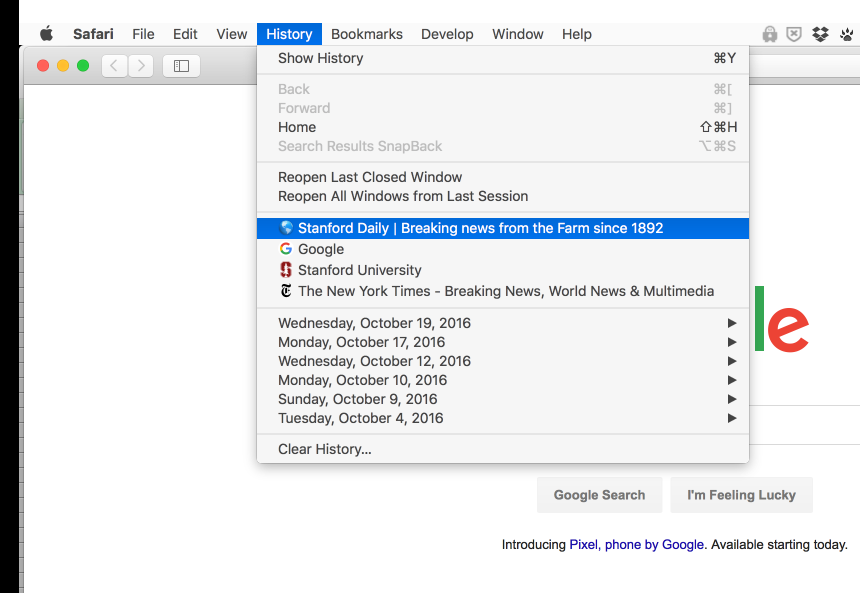
And here's my history according to Firefox:
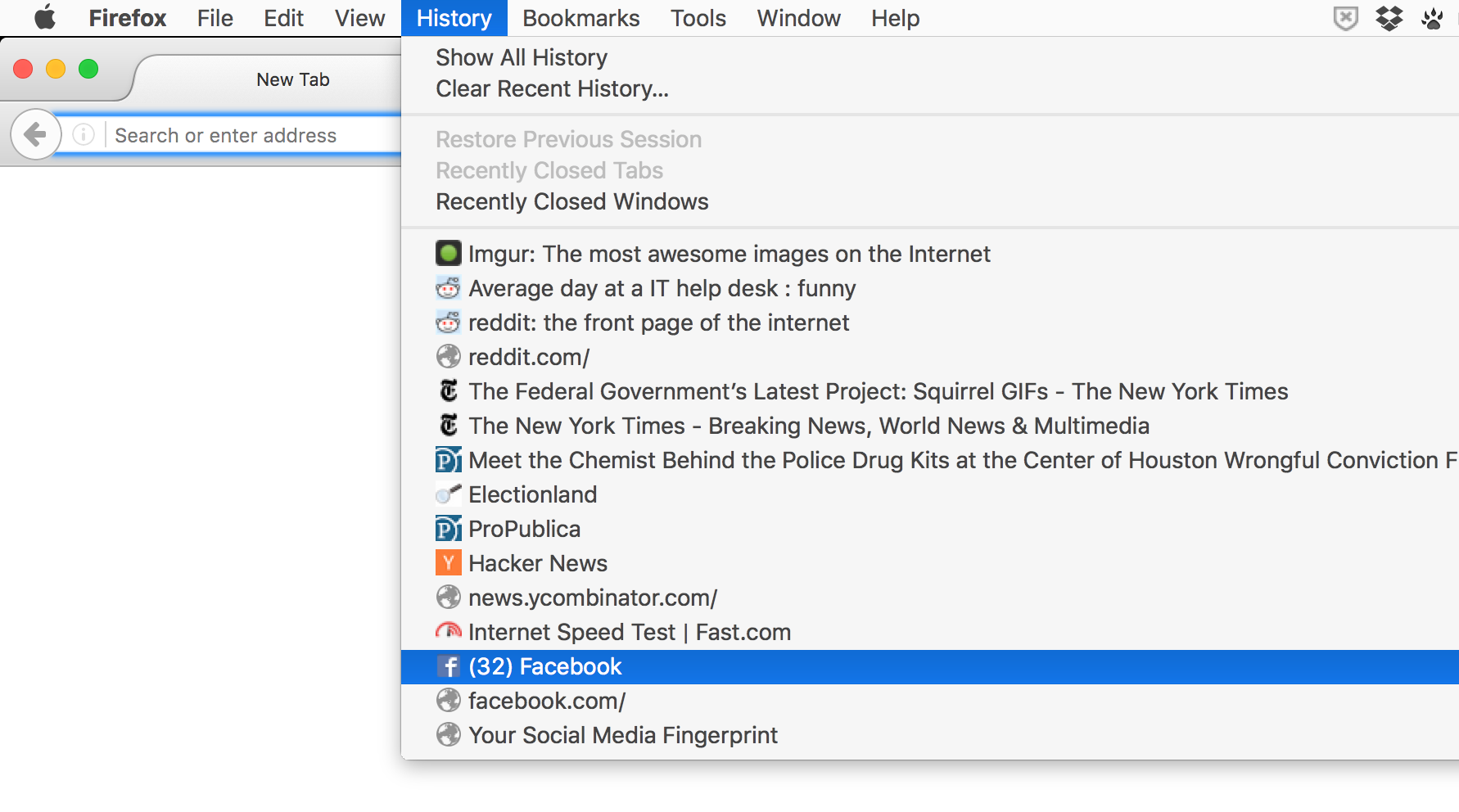
The listed recently visited sites are different for me because I use each browser separately, and each browser has its own file directory for storing user data files, and their own schema for their SQLite databases.
While the actual data has a few big differences between the browsers, the user-facing part of the history data – in particular, the History menu – should feel the same. For the most part, they have:
- A menu item to the tune of Show All History, which opens up a History panel dedicated for showing the entirety of the data.
- A menu item to Clear History.
- A short list of the most recently visited pages. Even though webpages are primarily identified by their URL, URLs aren't often friendly for humans. So, the listing for
https://projects.propublica.org/electionland/is "Electionland".
Going back to Safari's design, we see that it not only lists a few recent individual URLs, but has a list of dates, each containing their own submenu of links:
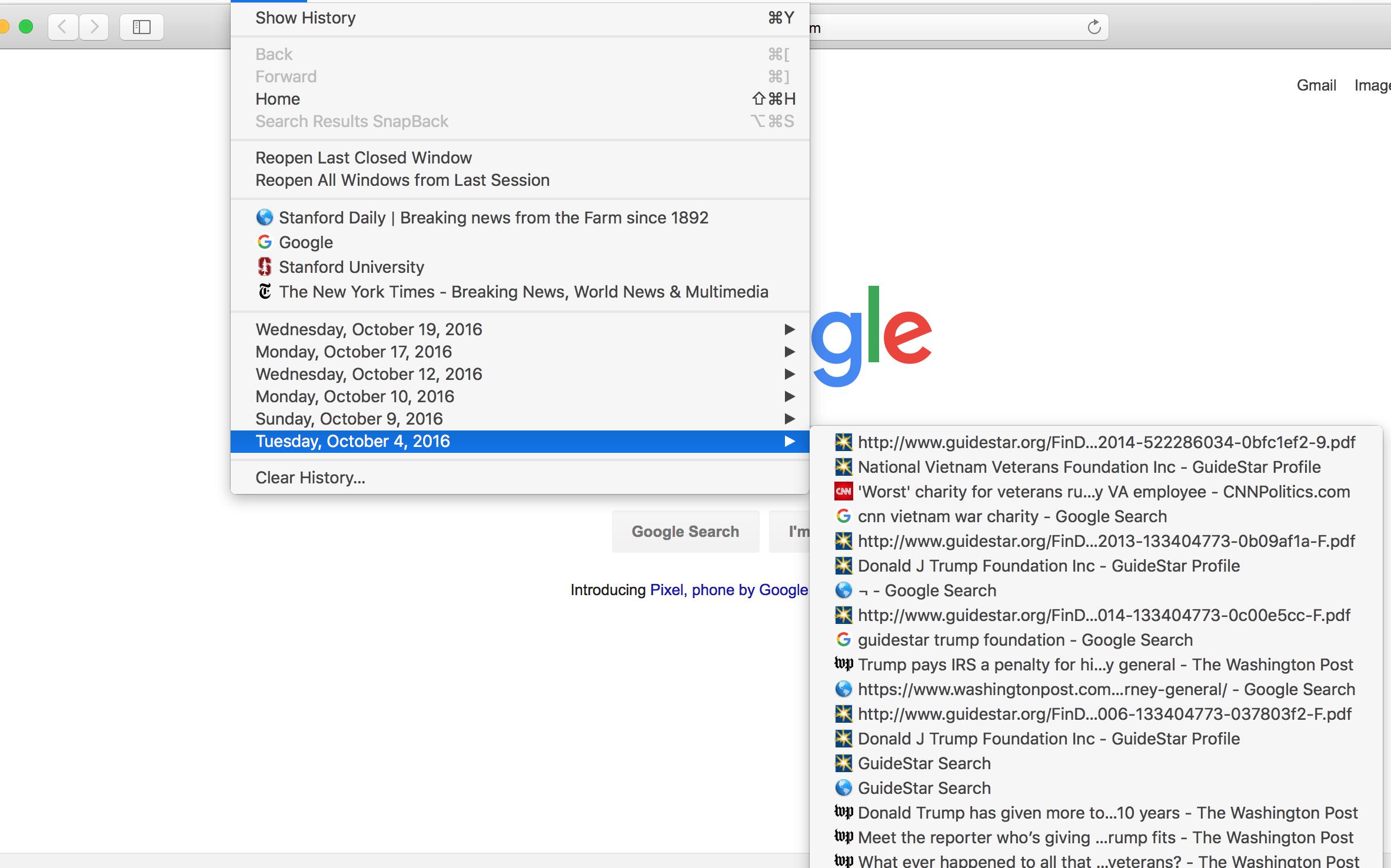
If you asked me what web pages I visited on October 4, 2016, I wouldn't have a clue. If you told me that my browser history shows a bunch of visits to stories about the Trump Foundation and to Guidestar – still wouldn't ring much of a bell. But if you told me it was a Tuesday, I would immediately remember that that was a lecture day, with the topic of investigating non-profits and 990 forms.
However, without any kinds of clues about what else happened on a day, the routine, frictionless nature of web browsing – and constant connection to the Internet – make it extremely difficult for anyone to recall what webpages they visited, when they did so, and why.
The History menu can only show so many links, and a user's history could contain tens of thousands of webpage visits. So each browser has a full History panel (with a keyboard shortcut of Command-Y):
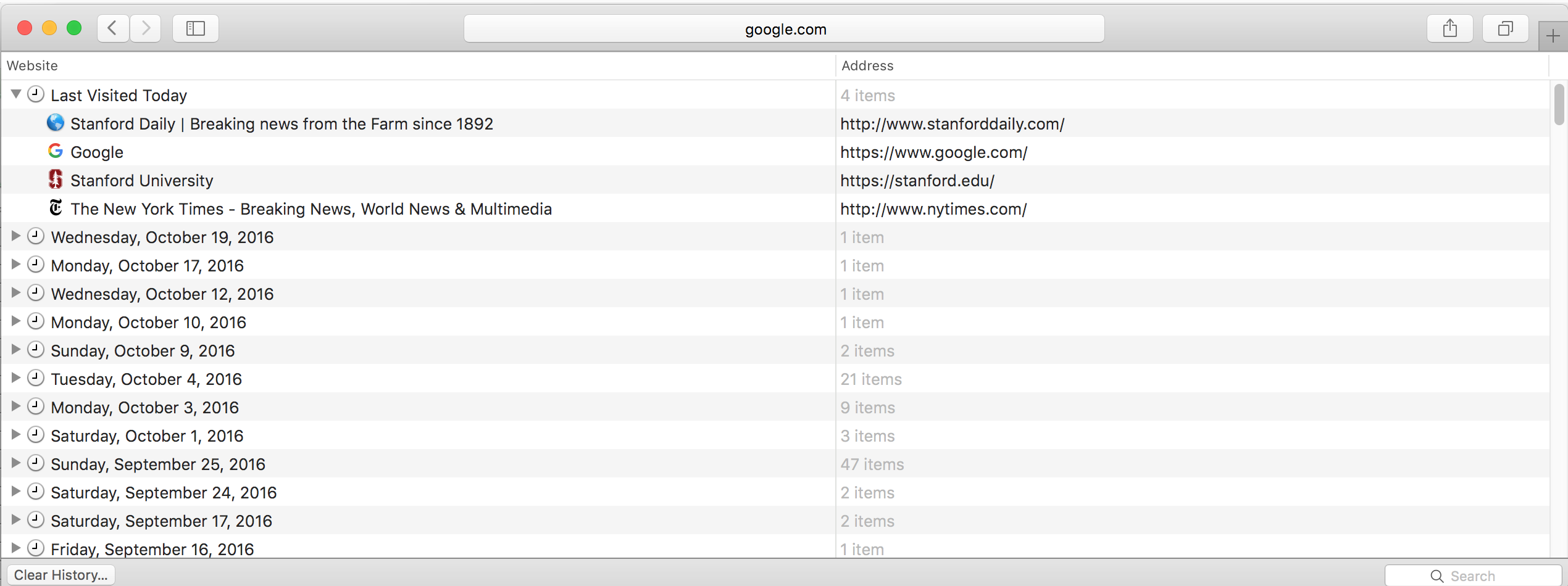
It's not a lot of fun to scroll through hundreds or thousands of links, so the History panel has a little search box to do some quick filtering. On
As you can imagine, this database has great value to certain parts of our judicial system. In the case of People v. Zirko, the defendant's browser history, which contained visits to sites such aswww.private-investigator.com and www.anesthesia-nursing.com/ether, was used by the prosecution to bolster their case that Mr. Zirko planned the murders of his former girlfriend and her mother.
But you don't have to be a murder suspect to be at risk of being impugned by your own browser history. The Daily Dot in 2014 wrote about a Chicago TV reporter whose past visits to Pornhub were revealed during an innocuous promo:
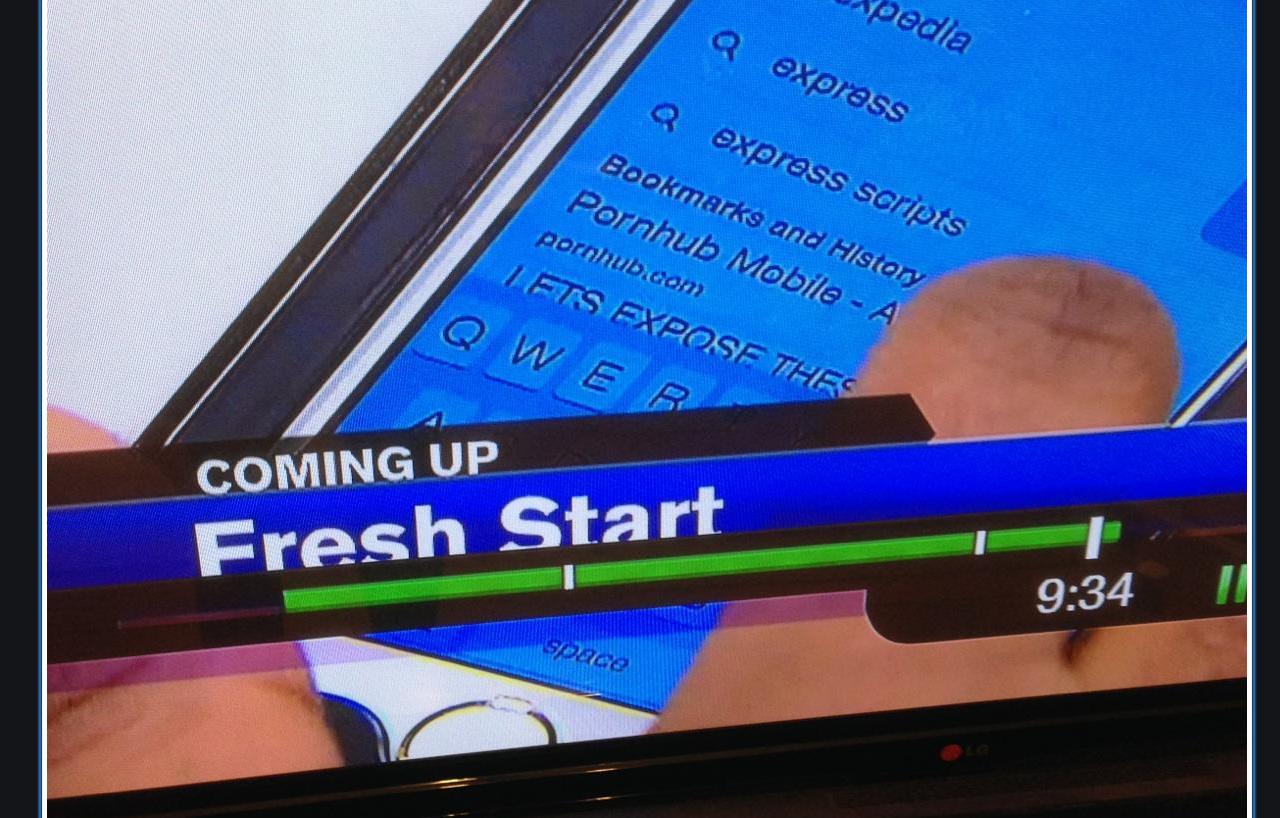
A sidenote about clearing history vs. trashing your database
In this section, I started to document how clearing the history in your browser should result in the database file being emptied, the same effect of you deleting Safari's History.db using the Trash can.
It's not quite that simple. Emptying all of your history does not seem to affect the database file right away. And yet, the database, when opened in SQLite, is empty.
The reality of how we browse the web today is too complicated for web browsers to assume that only one user/device is accessing the associated user's data.
For example, modern iPhones and iOS have the option of syncing the bookmarks and browsing history on your phone with the data on your desktop. This syncing process is something that happens regularly and at any given moment.
I have an iPhone and I use it to browse the web on the phone. Sometimes I like to multitask by browsing on my desktop, while phoning it in. What chaos happens when I visit a web site on my iPhone, but at near the same time, visit a different site on desktop Safari? Both Safari's have to record to the database, it's possible that they could hit up the database file at the exact time.
This is an extremely common yet fundamental challenge in computing. But the reliable and consistent syncing of data is something SQLite and other databases solve. That's why SQLite is used everywhere.
But two different devices trying to write to the same database is a much easier problem than one device destroying a database while the other is trying to write it.
This is all a very long way of saying: we're only concerned about databases, not how web browsers work together in the cloud.
What Chrome and Safari think about humans and time
Chrome's prompt for clearing browser data is: "Obliterate the following items". The label for the most extreme choice is: "the beginning of time". The language may seem over the top, as there's not really a difference between "obliterate" and "delete" to a computer. And "beginning of time" could just be hardcoded to Jan. 1, 1950, or whenever the first web browser made the rounds.
But as humans, the trend in our lives is to cede control to computers. When we need to dispose paper, we can shred and burn it to our complete satisfaction. But when we press the "delete" button, we have almost no physical confirmation or closure. And this isn't even considering how we have no power to delete data held by "the cloud".
With information and wealth so ephemeral in today's world, over-the-top words is better than nothing.
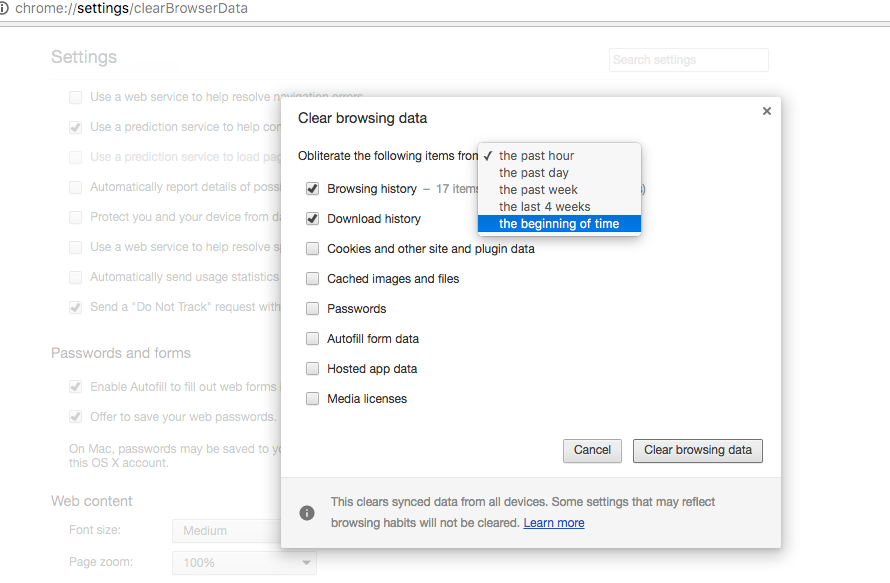
Chrome let's us wipe out data in the past hour and in the past day, for situations of immediate regret. The next time interval is a week's worth of data. And the next option is 4-weeks, for users who do want to scrub their histories, but aren't sure if they can go all the way.
In contrast, Safari is taking the Marie Kondo approach, seeing history-clinging users as hoarders who must not be given an excuse to wipe clean their mess. no room between a couple of days of history and total nothingness. With Safari, you have the option to erase what you did in the last hour, day, or 2 days. Need 3 days? Sorry, you're going to have to nuke the entire database:
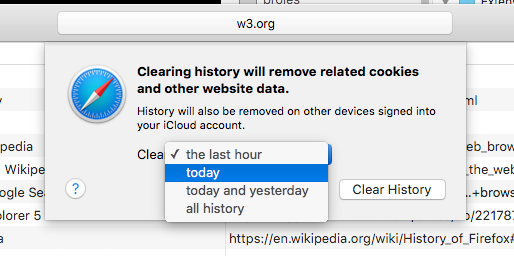
Seems cruel of Safari to not offer one more option so users don't have to erase everything. But I believe its approach is more commendable, and has a better appreciation of the human experience.
How many webpage visits can you remember from 2 days ago? Assuming you didn't nuke any scandalous page visits that day, can you remember if any of those pages were controversial enough for you to regret if someone found out about them today?
No? Then why do you think you'd have any idea what you did a week ago. Or 4 weeks ago? Nuke it from orbit, it's the only way to be sure.
Computers, humans, and the beginning of time
A nice Spaceballs clip, to illustrate how fuzzy we humans are when it comes to describe when things happen:
There are some issues with the SFPD's crime incident log, but as far as crime data goes, it's easy to understand at a glance and detailed and deep enough for interesting analyses.
There's even a gesture for human-readability. The incident timestamp format is straightforward (to Americans, anyway); date and time are in their own columns: 10/06/2016 and 22:05.
When it comes to crime, we not only care about the exact date and time of day. But we care about which day, because crime numbers correlate with weekend activity and work schedules. So the SF data has a separate column, DayOfWeek. No need to consult a calendar.
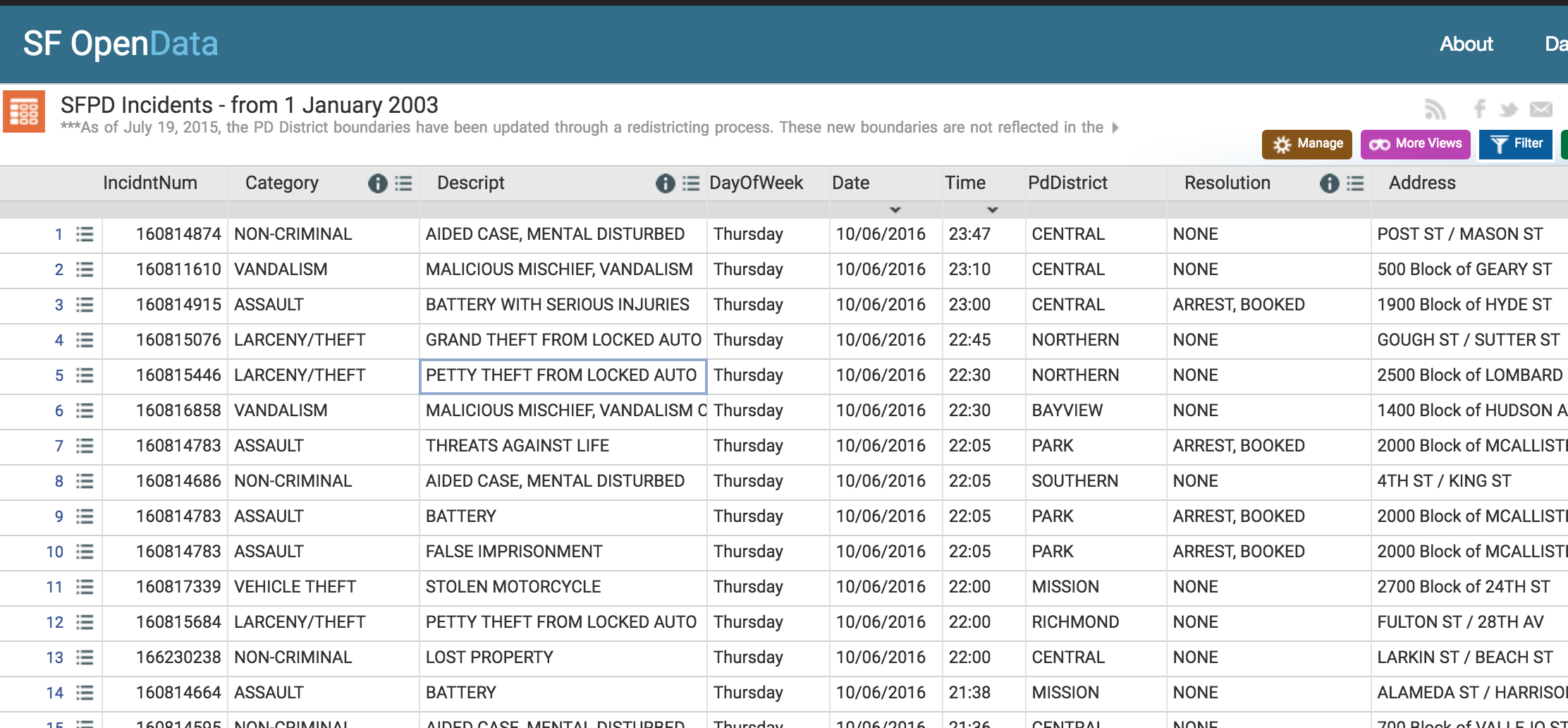
I have no major gripes. As a programmer, it's easy enough for me to wrangle the time into what format I want, a single column: 2016-10-06 22:05.
So let's evaluate how SFPD does time by comparing their datatime format with how Safari browser tracks time in its databases. The relevant column in Browser.db: is history_visits.visit_time:
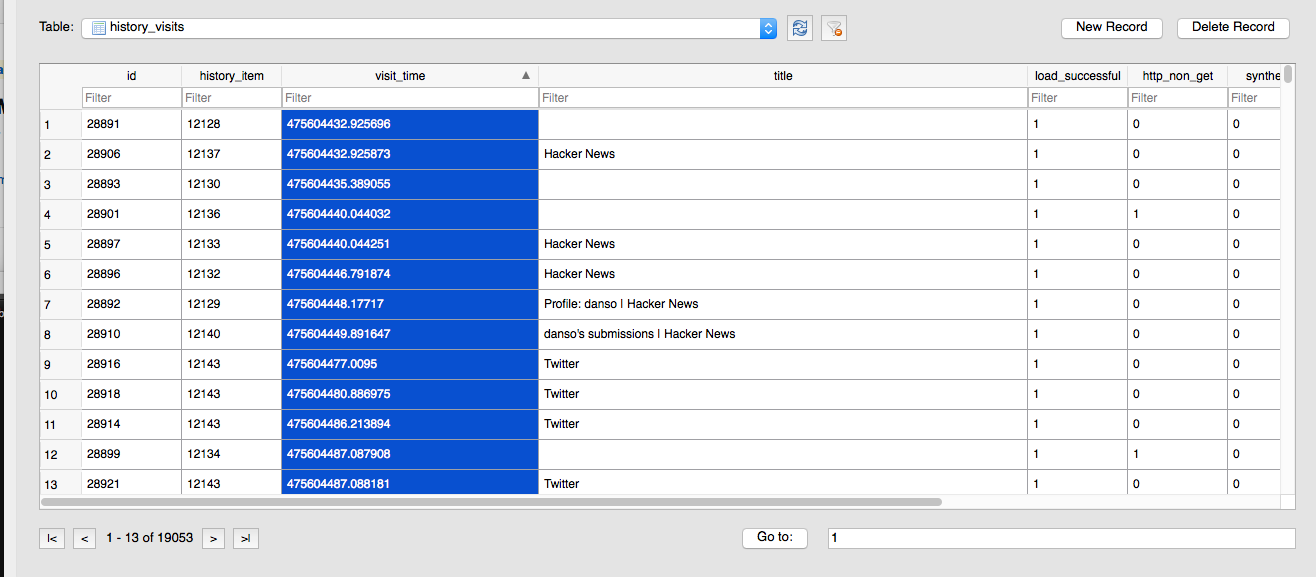
Safari's opinion on the beginning of time.
This doesn't look like any timestamp normal people use:
475604432.925696
475604448.17717
475604449.891647
475604477.0095
The integer part of the number represent seconds: 475604432. The decimal part is, well, fractions of a second.
But what does that mean? It'd be as if you asked me when I was born, and I said, "In the 273215823th hour".
But it's not completely unheard of. If I responded with, 1968, you could fill in the blanks: "Dan was born in the 1968th year since the Year of Our Lord"
Apparently, the developers of Safari, don't hold 0AD as sacred: 475604432 is not 475604432 seconds since the birth of Christ. It refers to 475604432 seconds since January 1, 2001.
Why can't Safari record time like SFPD and all the other agencies?
To sum things up: SFPD data will always, in every conceivable scenario, be recorded and analyzed with the assumption that Pacific Standard Time is the timezone.
Your web browser, and all of your other software, does not.
Revisiting Excel
Excel is not different than SQLite when it comes to treating data as a type, e.g. 99 is a number and "99 bottles" is a text string. Excel is just more willing to obfuscate the reality of its data so that things are more readable to the average human.
For example, if you're going to store a date in SQLite as a string, this is by far the most popular convention:
YYYY-MM-DD
e.g.
2016-10-03
Type that into an Excel cell, but surround it in double-quotes so that Excel treats it as a literal string value:
"2016-10-03"
In the next row, type in the same date, except leave out the quotation marks. As soon as you hit enter, Excel will autocorrect the appearance of the cell to fit a more American way of dates.
10/3/16
Finally, type in 10/16, sans quotes. What will Excel do? Will it interpret 16 as the year 2016? Or 16 as the day 16.
Seems to be the latter, but for whatever reason, Excel has decided to make a new date format:
16-Oct
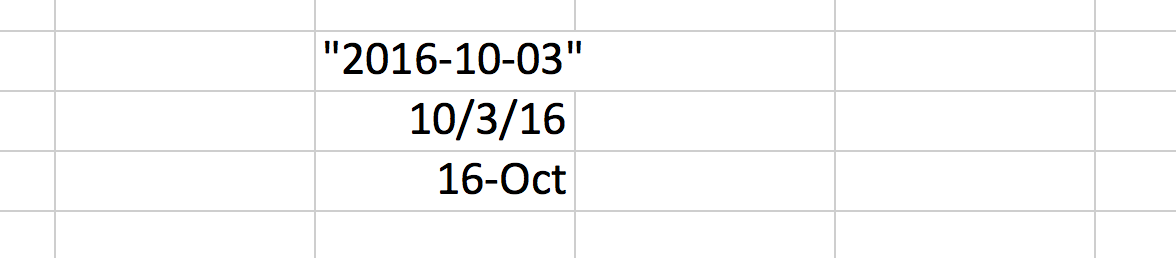
OK, let's explicitly choose how we want to format our cells.
Highlight the 3 data cells. Choose Format > Cells… from the menu.
Select Custom category, and then specify the type in Excel's special shorthand code:
yyyy-mm-dd
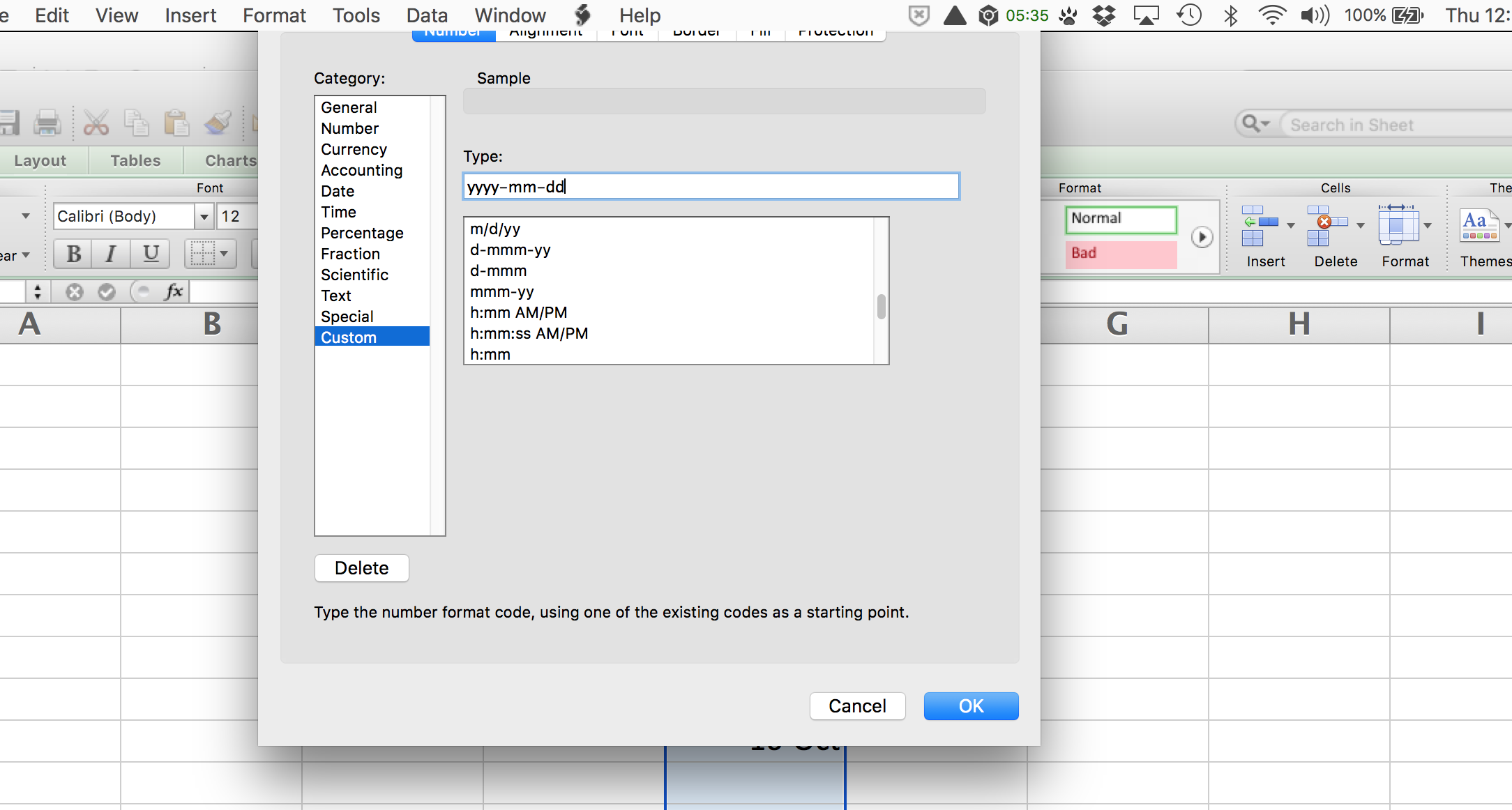
The result is pretty much what I would expect:

But things aren't exactly as they seem. The top value, with its double quotes, is clearly treated like something else. The easiest way to confirm this is to do a formula transformation and extract the year as a number:
=YEAR(E8)
The result: that first value of "2016-10-03" is not considered by Excel to be a date.
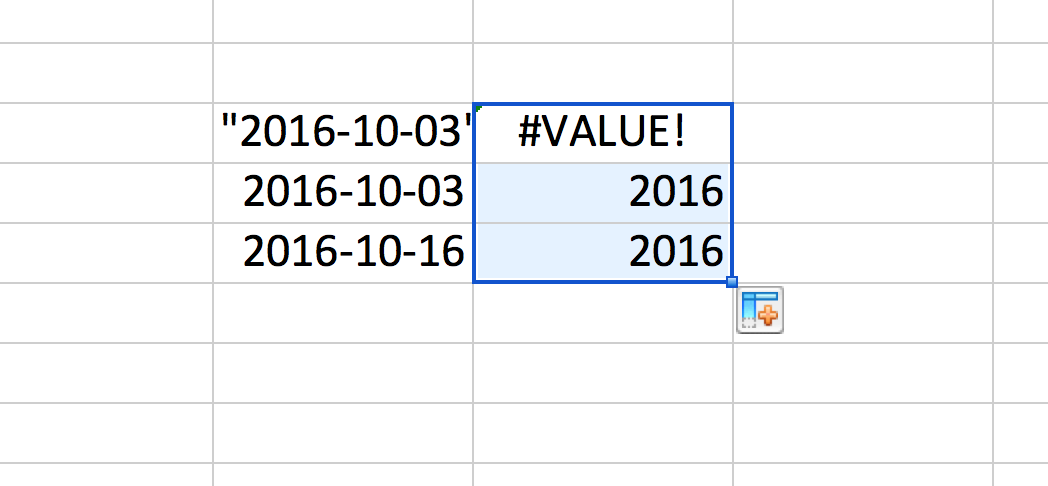
OK, whatever. Let's cut our losses. Delete that year column. And let's pretend we need to export the data. But we're worried that somewhere in the porting process, 2016-10-16 will go back to looking like, and being a string literal value, e.g. "16-Oct", which is very annoying when importing to a database.
My instinct and only idea is to tell Excel to convert the values to text. That is, I don't care that Excel sees 2016-10-16 as a date. I don't want it to do any more formatting for me, just give me a literal "2016-10-16". Excel can even surround the value in quotes if it makes Excel happy.
Going back to Format > Cells, I choose the Text category. Look at the description – "The cell is displayed exactly as entered" – how is that not exactly what I want?
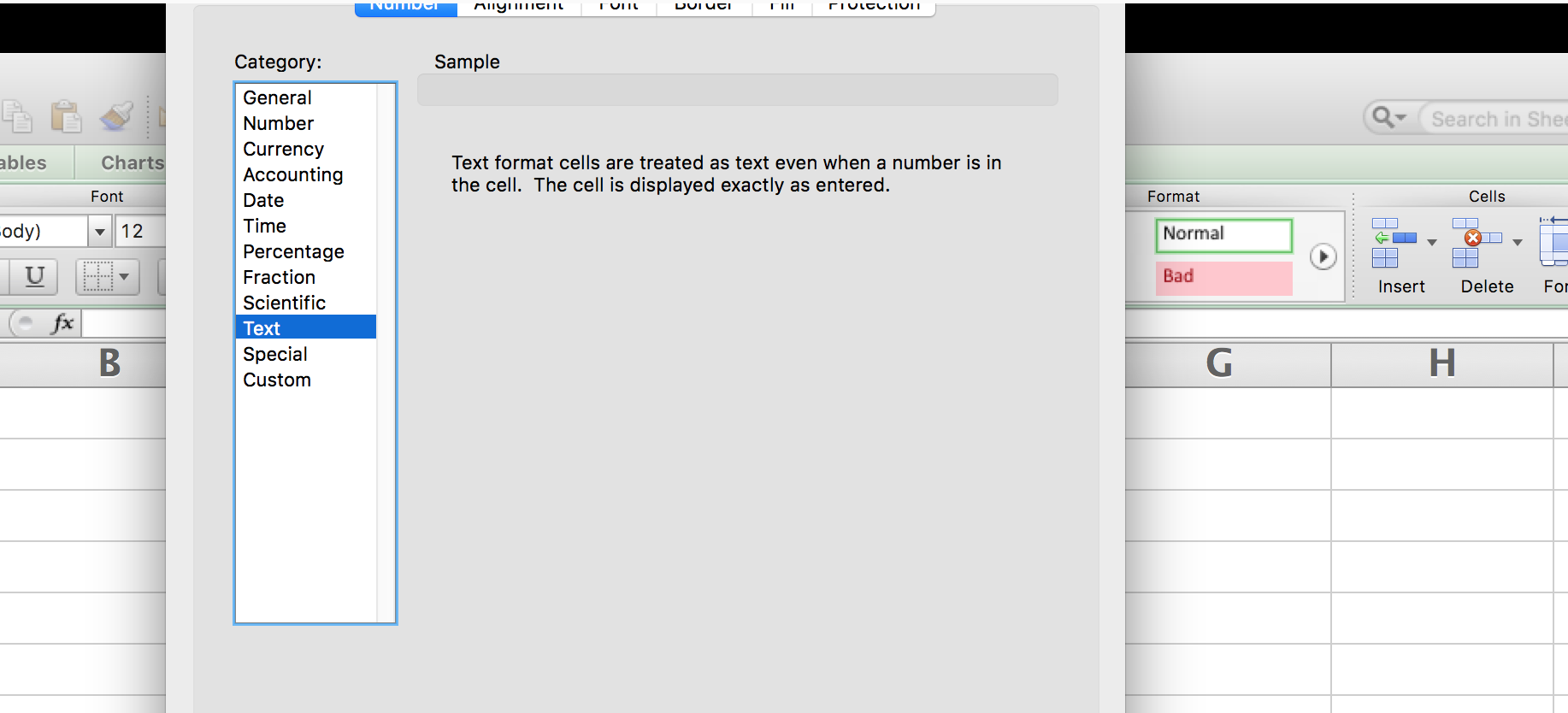
I honestly don't know what to expect, but I can't say I'm disappointed:

As it turns out, Excel as its own arbitrary way of deciding numbers. It doesn't count seconds, it counts days. And what does Excel think to be the beginning of time?
January 1, 1900.
But wait, which Excel on which kind of computer do you have? Because it might be 1904.
Time is hard. SQLite's way of managing it is kind of confusing. But in time, you might see that it's the sanest way to deal with time…
Sample queries on Safari History.db
- How many webpage visits total does the History database contain?
This is easy. history_visits has a row for every visit:
SELECT COUNT(*)
FROM history_visits;
But we can use history_items, too, as every URL has a corresponding visit_count:
SELECT SUM(visit_count)
FROM history_items;
- How far back does the database go?
Sort by history_visits.visit_time in ascending order:
SELECT visit_time
FROM history_visits
ORDER BY visit_time
LIMIT 1;
The result is meaningless, or at least really difficult to calculate: 475604432.925696
Following the pattern described in this answer – it helps to understand that "Unix time" has its own beginning of time: 1970. Safari's epoch is in 2001. The difference between those two times, in seconds, is: 978307200
SELECT
datetime(visit_time + 978307200,
'unixepoch', 'localtime') AS dantime
FROM history_visits
ORDER BY dantime
LIMIT 1;
The answer: 2016-01-27 08:20:32
- How many webpage visits a day on average?
We don't need to use datetime. We just need to separate the oldest visit_time from the newest visit_time. The answer will be the timespan in seconds.
Then we divide that timespan by how many seconds are in a day, to get the time span in days.
Then we divide the total count of visits by number of days.
First step, difference in seconds:
SELECT
MAX(visit_time) - MIN(visit_time)
FROM history_Visits;
Divide that quantity by the number of seconds in a day:
SELECT
(MAX(visit_time) - MIN(visit_time)) / (60 * 60 * 24)
FROM history_visits;
The total number of visits is the count of rows in history_visits
SELECT
COUNT(*) / (MAX(visit_time) - MIN(visit_time)) / (60 * 60 * 24)
FROM history_visits;
Final answer, 9.5 URLs per day.