Getting Started with Carto Builder
Logging in, creating a dataset, and making a map with Carto Builder and USGS Earthquake data.
Get a dataset
About Carto and Carto Builder
What is Carto? Just a website to build, design, and publish data-heavy maps.
Carto gives us state-of-the-art geospatial visualizations backed by all the modern database we need. I can't think of another service that is as adept at meeting the needs of novice and expert data explorers and designers.
If your work has any element of geography to it, Carto will likely be the best place to start and even finish.
Currently, Carto offers a free plan: you can sign up at https://cartodb.com
But wait, you Cardinal
However, if you are affiliated with Stanford and have a working @stanford address. you'll want to sign up at stanford.carto.com/signup:
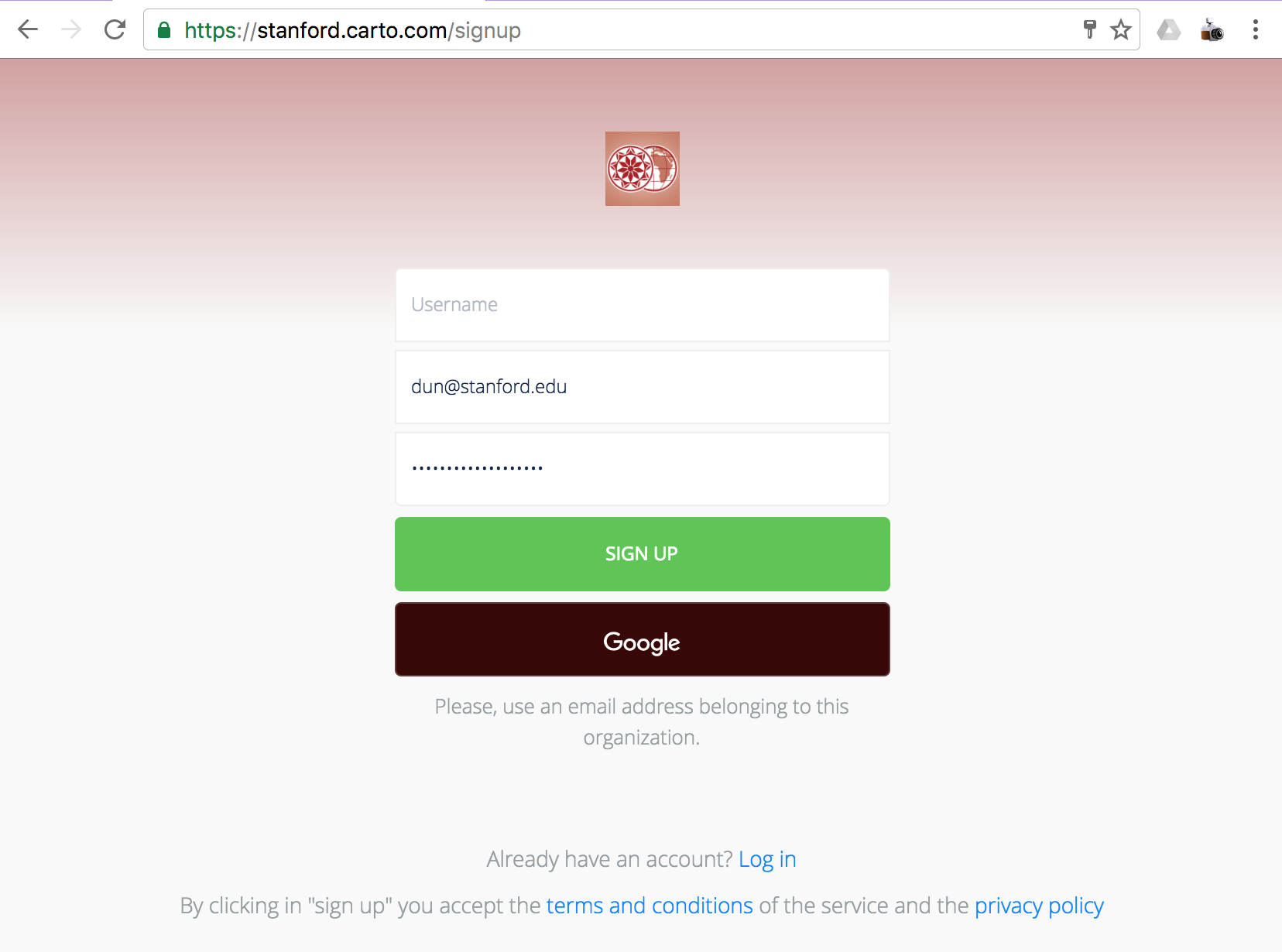
I'm not privy to the deal we have with Carto. But the main difference as of October 2016 is that we get access to Carto's new interface. If you sign up at Carto's legacy site, you'll have, as far as I can tell, most of the same functionality. But I don't want to make two different sets of screenshots pointing out where to click.
First login
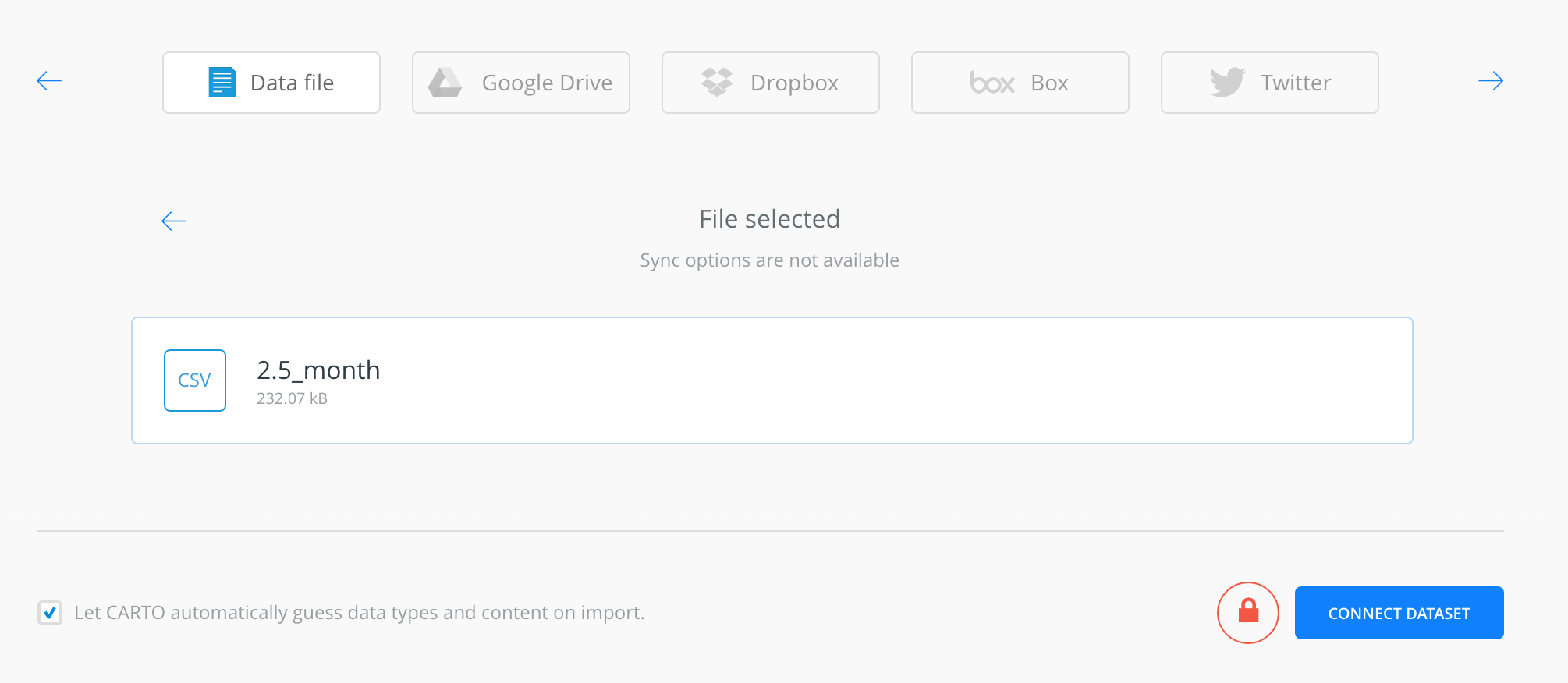
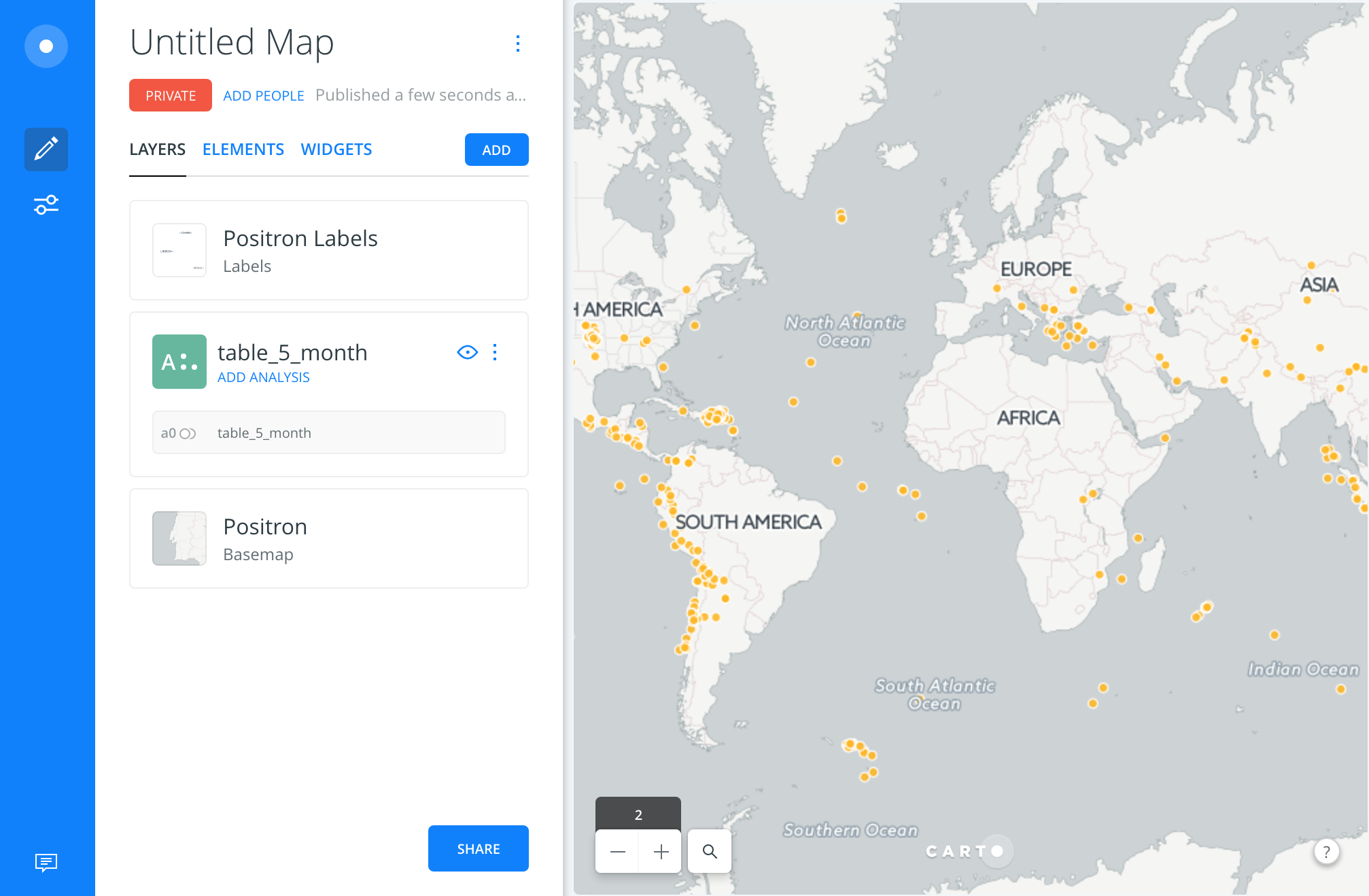
Connect a dataset
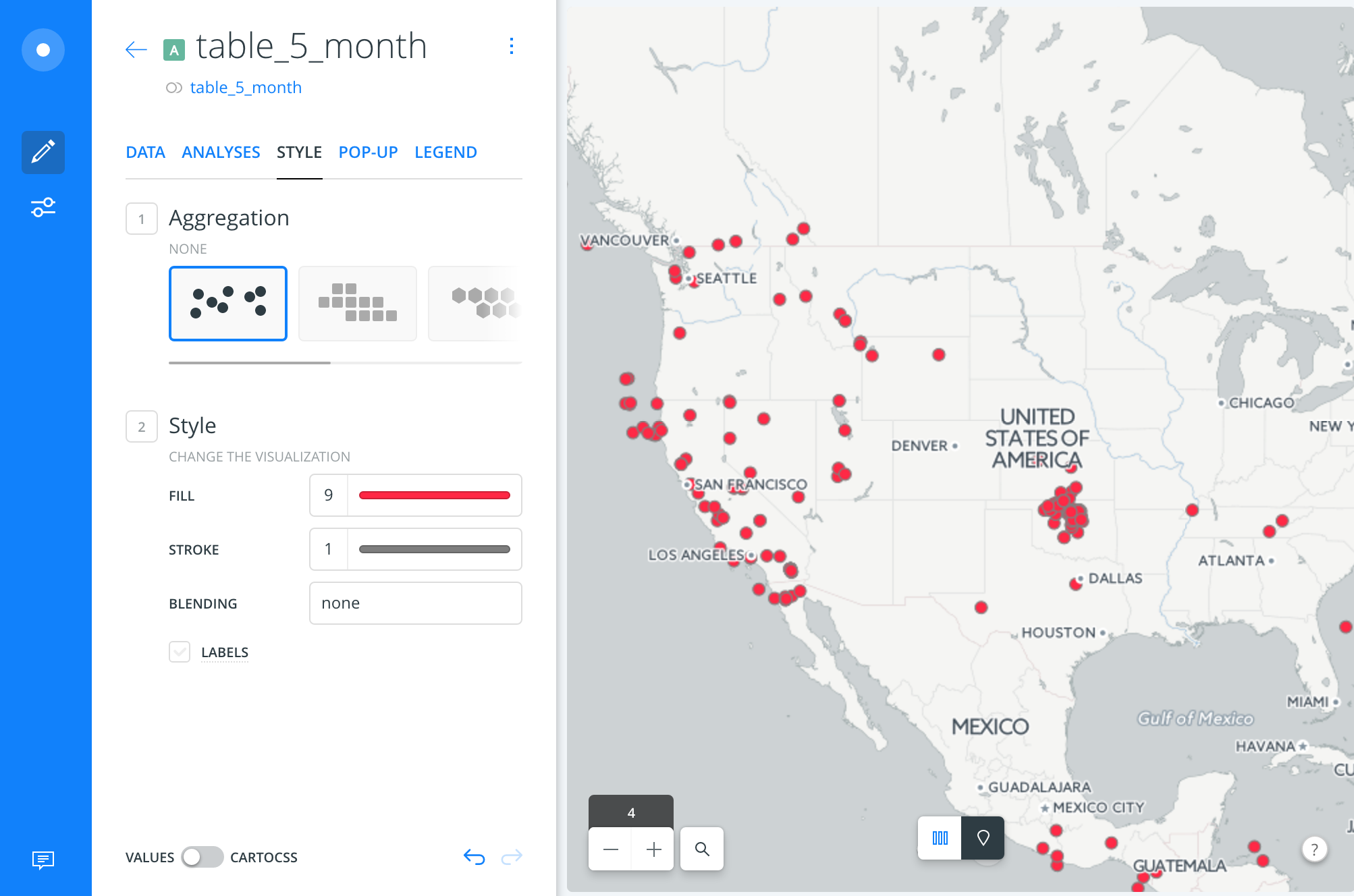
Style a dataset
Click on the Style subhead.
Style some basic colors, such as the fill and stroke color:
Play around with the types of aggregation. Think of aggregation as doing a group-by in a Pivot Table, except we're doing that grouping by geospatial coordinates.
The square-bin option can be thought of as putting all of the earthquake points into a nearest square bin. When the selected Operation is Count, then the darkness of the bin represents the number of points in a given bin.
Try changing the Operation to SUM, and choose mag as the column to sum:
Now the bins are colored based on the sum of the magnitude values of its respective earthquake points. Which is probably not helpful in most real-world analyses of earthquake impact, because 100 magnitude 2.0 earthquakes is not at all as interesting to us as a single M8.0 quake, assuming "us" refers to humans who depend on human-built physical structures.
With that in mind, it might be more interesting to use the MAX operation for binning. Now the darkness of a square bin is determined by the biggest earthquake to hit in that bin's area:
Return to data
A lot of Carto's feature and design is optimized for users to think about things visually. But underneath the slick web interface is the same data that we see in any spreadsheet and database.
The Data sidebar
Click the Data subhead; the right-side of the interface will probably stay the same, but the left-side will reveal a sidebar of datapoints about our datapoints, e.g. "point count", and various histograms showing the distribution of values:
The Data table view
To focus the right-side on the raw data, at the bottom of the map, there's a mini-icon bar that represents the two kinds of data views: tables and points. Right now, points is active, so click on the other icon to see the tables view:
![]()
And here's the raw data in table form:
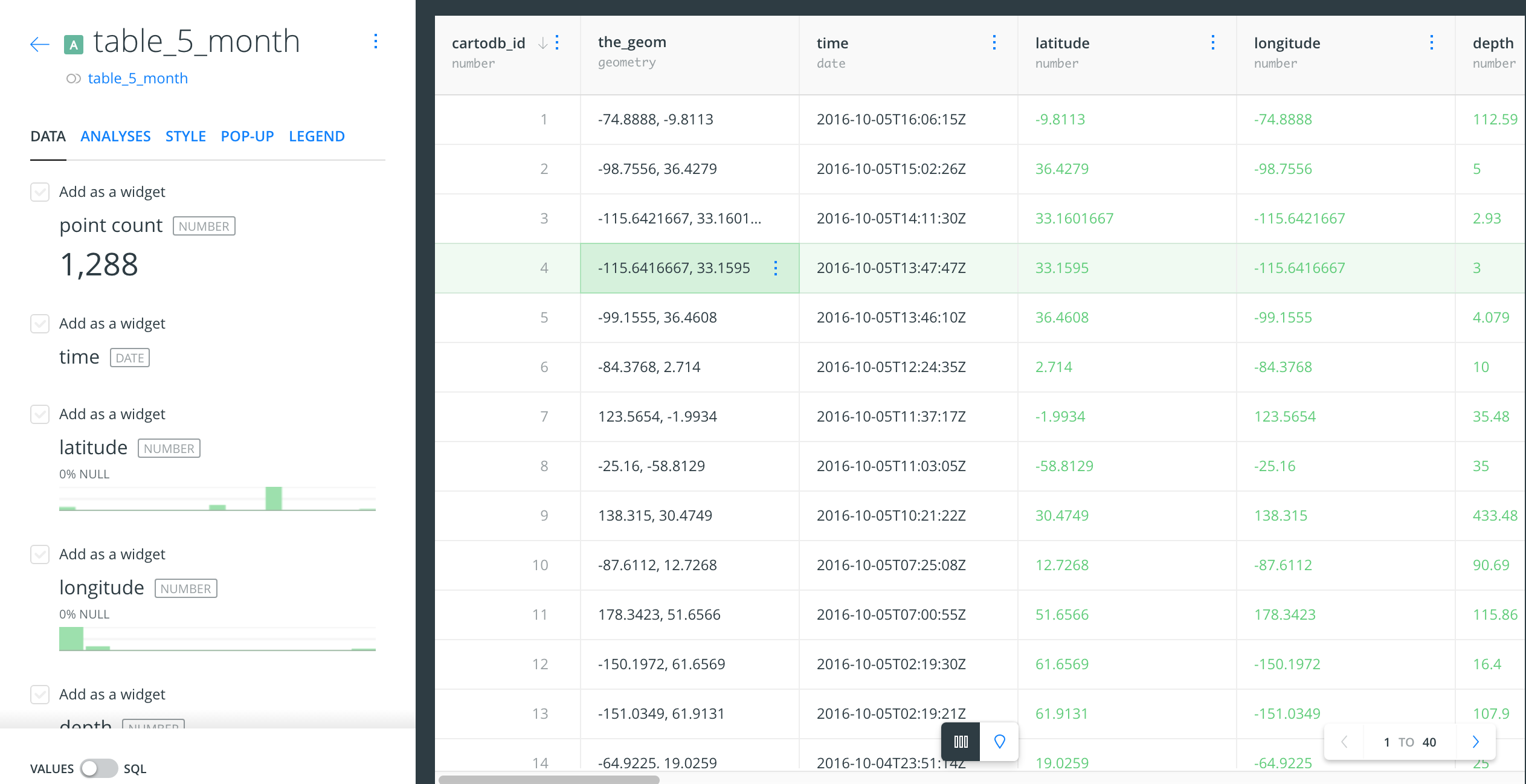
Differences
Just a spreadsheet, right?
A couple of things to note. First of all, the import process added a couple of Carto-specific columns, cartodb_id and the_geom. Pay them no mind, these are for Carto's internal use.
Second, unlike a spreadsheet, the process to sort and rearrange the data, nevermind just editing a cell, is very rudimentary and clunky compared to a modern spreadsheet:
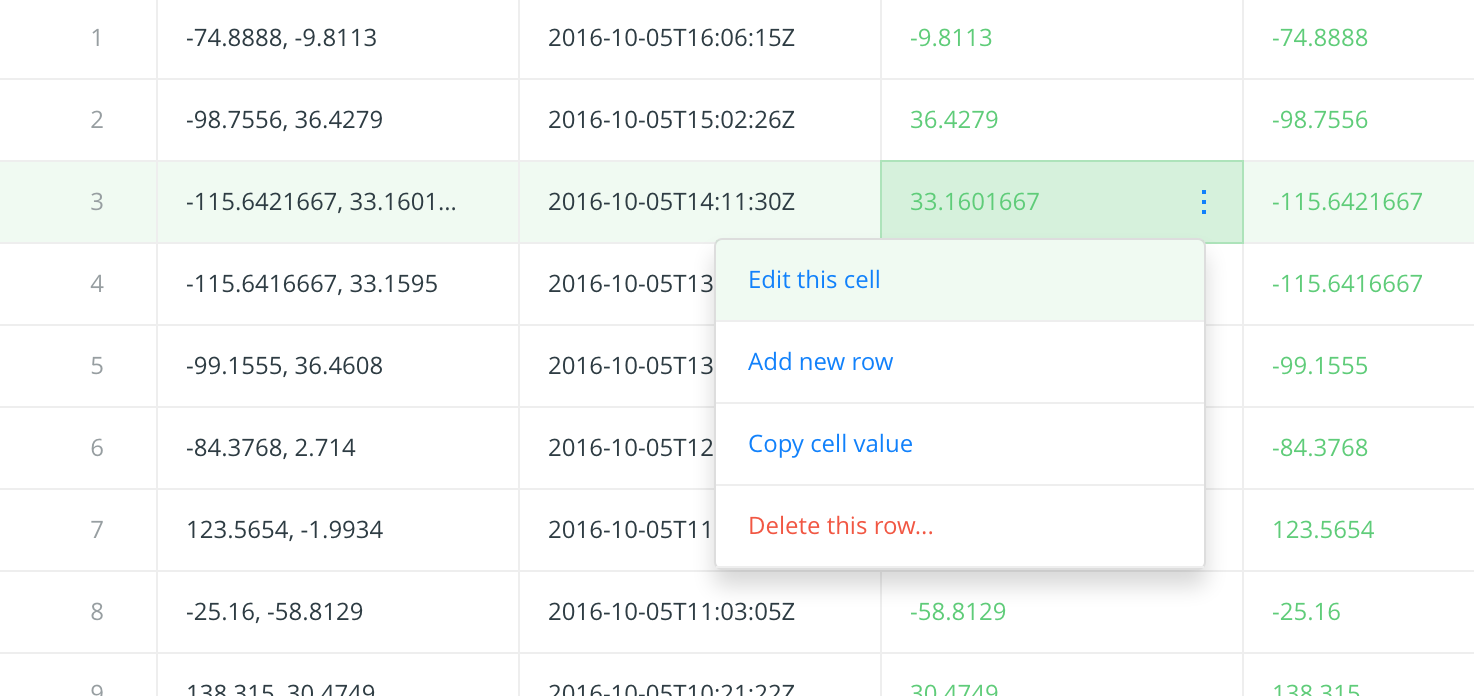
That's because it's not really a spreadsheet, it's a database. When we imported our raw data CSV into Carto, it stored it into a SQL database (PostgreSQL to be exact). Databases, if you haven't learned already, are not really meant to be freely interacted with in the way that spreadsheets are.
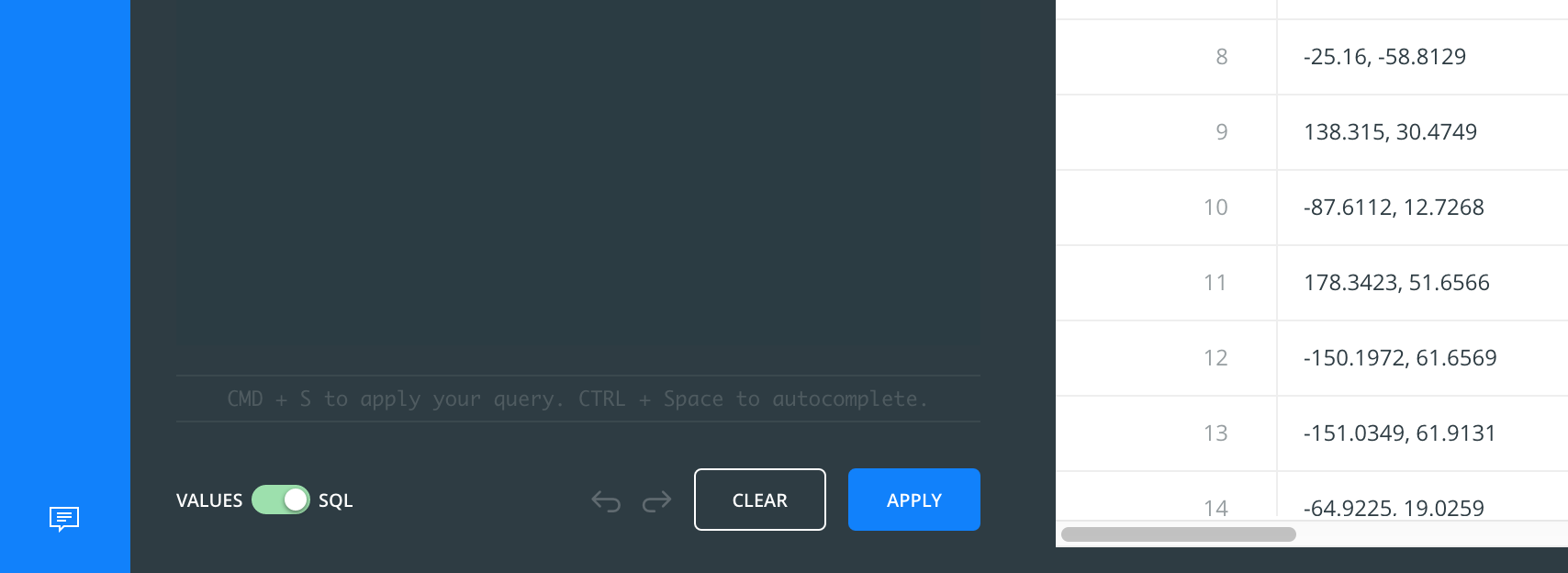
In fact, we will rarely be interacting with the data sidebar or the table, via the GUI. Instead, we'll be using SQL mode.
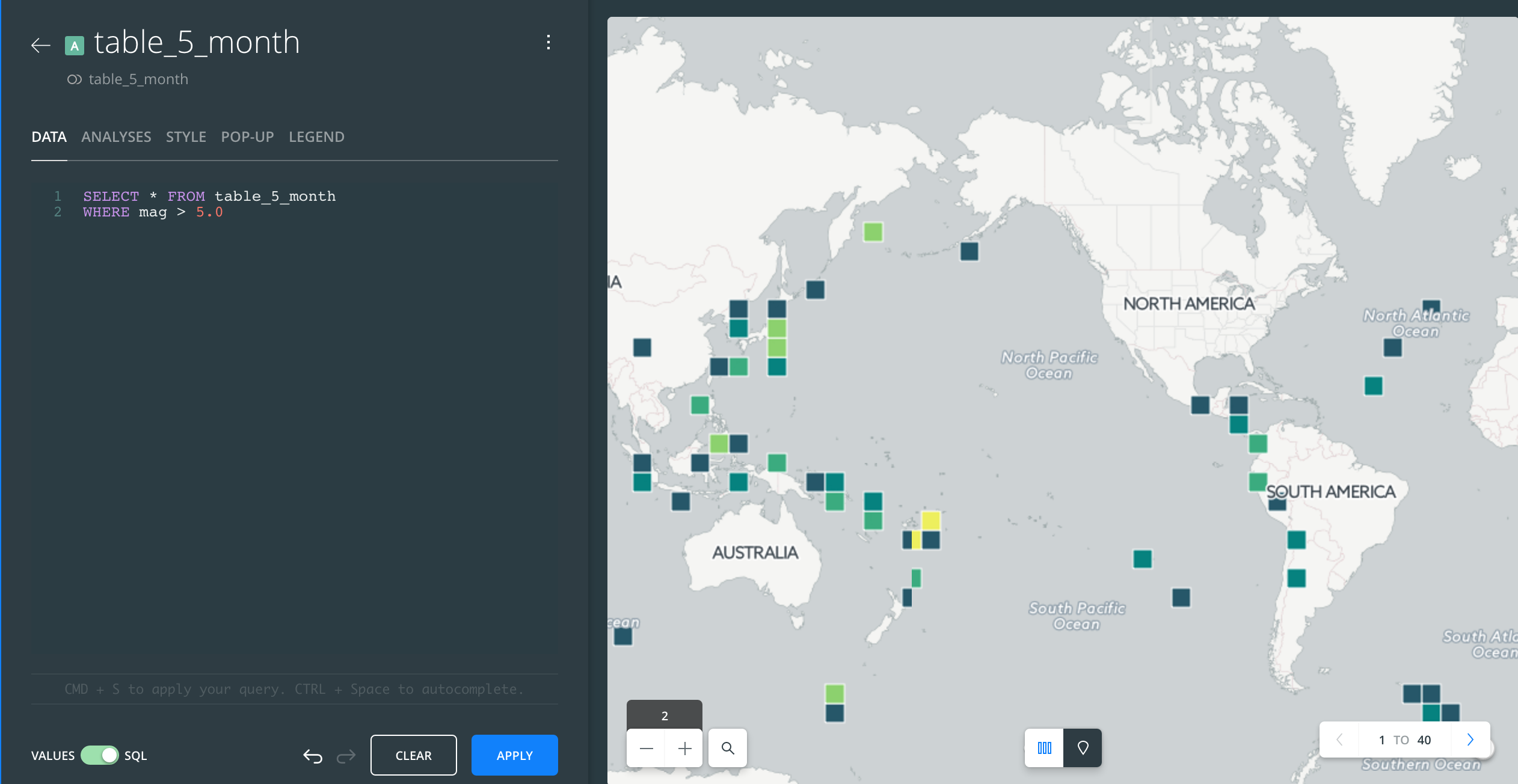
You can get to SQL mode by directing your attention to the bottom of the left-panel Data sidebar where there's a toggle for Values and SQL:
While we're at this step, go ahead and switch the right-panel to the Map view:
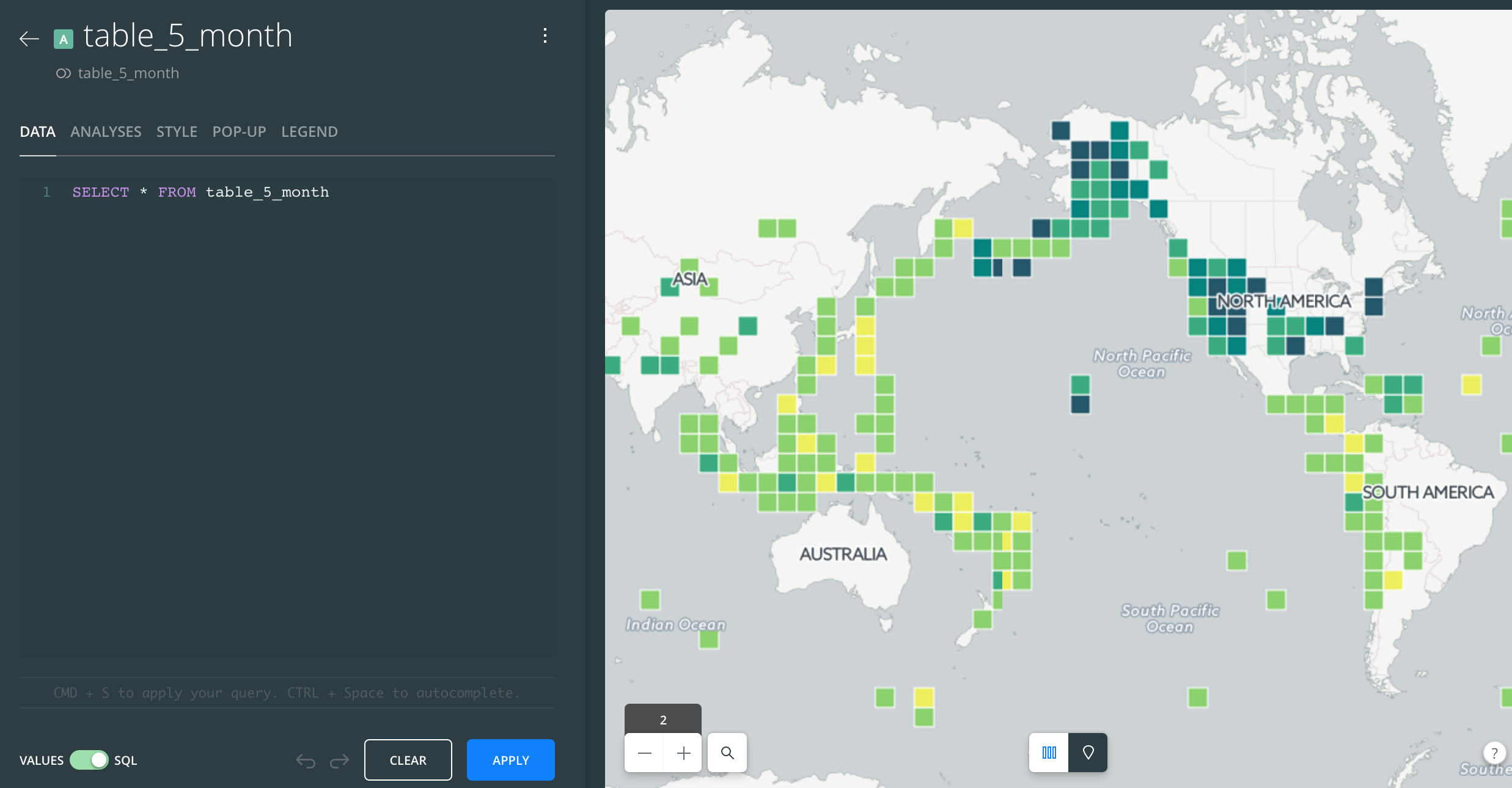
And if you know any SQL, go ahead and write it and hit the Apply button.
In the example below, I've written a SQL query that effectively filters the dataset to earthquakes of magnitude greater than 5.0. And as we'd expect, that results in far fewer datapoints on the map:
There are several other aggregation methods, including animated heatmap (also known as a torque heatmap). Animation brings its own set of tradeoffs and concerns, but it's fun to explore the options and get a feel of how they perform, and how the structure and depth of your dataset is a major factor in choosing an effective visualization type.